
هتروژنیتی یا ناهمگونی (Heterogeneity) در فراتحلیل (Meta-Analysis) به معنای وجود تفاوتها و پراکندگیها میان نتایج مطالعات مختلفی است که قرار است در یک تحلیل آماری با هم ترکیب شوند. در فراتحلیل هدف از ترکیب دادههای پژوهش های مختلف، رسیدن به یک برآورد کلی از اندازه اثر یک متغیر مستقل (مداخله یا Intervention) یا رابطه آماری بین دو یا چند متغیر است؛ اما، زمانی که اندازه اثرها و داده های جمع آوری شده از مقالات مختلف تفاوت زیادی با هم دارند، این ناهمگونی به شکل هتروژنیتی نمایان میشود.
هتروژنیتی یک شاخص بسیار مهم و تاثیرگذار در نتایج گرفته شده از هر فراتحلیلی است. به همین دلیل، در تمام مقالاتی که از فراتحلیل استفاده کرده اند، شاخص های مختلف هتروژنیتی محاسبه و آورده شده است.
وجود هتروژنیتی بین اندازه اثرها میتواند به دو دلیل متفاوت باشد:
در فراتحلیل، وجود هتروژنیتی نشان میدهد که مطالعات کاملا مشابه هم نیستند و باید هنگام تفسیر نتایج به این اختلافات توجه کرد.
فرض کنید میخواهیم اثربخشی یک رژیم غذایی خاص بر کاهش وزن را بررسی کنیم. بعد از فرایند غربالگری (Screening) بر اساس استاندارد PRISMA، ده مقاله برای انجام متاآنالیز انتخاب شده اند. از بین این ده مطالعه مختلف، برخی از آنها روی افراد بالای ۵۰ سال، برخی روی جوانان ۲۰ تا ۳۰ سال و برخی روی افراد با بیماریهای زمینهای کار کردهاند. اندازه اثرهای بدست آمده در این مقالات احتمالاً یکسان نخواهند بود. این تفاوتها همان هتروژنیتی یا ناهمگونی در مطالعات علمی است.
واریانس آماری به میزان پراکندگی دادهها در یک مطالعه واحد اشاره دارد و معمولاً با فرمولهای کلاسیک آماری محاسبه میشود. اما هتروژنیتی به اختلاف و پراکندگی بین مطالعات مختلف مربوط است، نه درون یک مطالعه واحد. در واقع، واریانس آماری بیشتر به تصادفیبودن دادهها مربوط میشود، در حالی که هتروژنیتی بر وجود تفاوت واقعی بین شرایط یا نتایج مطالعات تاکید دارد.
تصور کنید یک آزمایش دارویی در یک شهر اجرا میشود و نتایج افراد شرکتکننده پراکندگی دارد؛ این پراکندگی همان واریانس آماری است. حال اگر همین آزمایش در چند شهر با شرایط متفاوت اجرا شود و نتایج بین شهرها اختلاف قابل توجهی داشته باشد، این اختلاف بین مطالعات همان هتروژنیتی است.
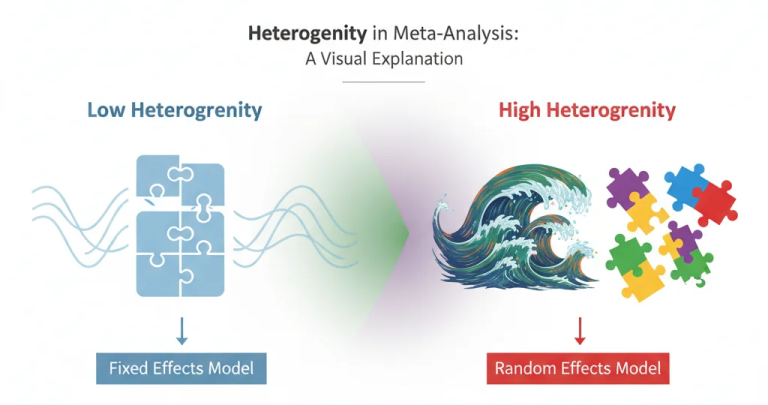
در مقاله مدل اثرات ثابت (Fixed-Effect Model) و مدل اثرات تصادفی (Random-Effect Model) مفصل صحبت کردیم که آنچه موجب انتخاب یکی از آنها می شود، ناهمگونی یا هتروژنیتی است.
هتروژنیتی در کنار پارادایم ذهنی محقق در مورد اندازه اثر، عوامل تعیین کننده انتخاب مدل مناسب (FE در مقابل RE) برای فراتحلیل است. به مقدار زیادی بر انتخاب مدل آماری و کیفیت نتایج پژوهش فراتحلیل اثر گذار است. در صورت وجود ناهمگونی بالا، استفاده از مدل اثرات ثابت (FE) ممکن است نتایجی گمراهکننده ایجاد کند؛ زیرا، این مدل فرض میکند همه مطالعات برآوردی مشابه دارند. در چنین شرایطی، مدل اثرات تصادفی (RE) بهتر عمل میکند؛ زیرا، میتواند تفاوت واقعی بین مطالعات را در تخمین نهایی لحاظ کند.
فرض کنید در چند مطالعه مختلف، اثربخشی یک دارو بر کاهش فشار خون اندازهگیری شده است. اگر نتایج بین مطالعات تفاوت قابل توجهی داشته باشد و از مدل اثرات ثابت استفاده شود، ممکن است نتیجه کلی اثر دارو بیش از حد و یا برعکس کمتر از واقعیت به نظر برسد. اما با استفاده از مدل اثرات تصادفی، اختلافها لحاظ شده و تخمین واقعیتری از اثر دارو بدست میآید.
هتروژنیتی در فراتحلیل به سه دسته اصلی تقسیم میشود که هر کدام با منبع و ویژگیهای خاص خود را دارا هستند. این دستهبندی کمک میکند تا پژوهشگران بتواند در فراتحلیل منبع ناهمگونی را شناسایی کرده و روش مناسب برای مدیریت آنها را انتخاب کنند. شناخت دقیق این تقسیم بندی در تفسیر صحیح نتایج متاآنالیز اهمیت حیاتی دارد؛ زیرا، بر انتخاب مدل آماری (FE و RE) و اعتبار نتیجه نهایی تاثیرگذار است.
۱. هتروژنیتی بالینی (Clinical Heterogeneity)
این نوع ناهمگونی یا هتروژنیتی ناشی از تفاوتها در ویژگیهای شرکتکنندگان (سن، وضعیت فعلی، متغیرهای توصیفی و …)، شرایط مشکل (مثلا نوع بیماری یا نوع اشکال در سازمان و …)، نوع مداخله (نوع درمان، نوع استراتژی و …)، یا عوامل محیطی بین مطالعات مختلف است. حتی اگر طراحی مطالعه و روش تحلیل مشابه باشد، تفاوت در شرایط واقعی اجرای پژوهش میتواند نتایج را متفاوت کند.
فرض کنید چند مطالعه اثر یک دارو را بررسی کردهاند؛ یکی روی بیماران سالمند، دیگری روی جوانان، و یکی دیگر روی بیماران با دیابت نوع ۲. تفاوت در سن، وضعیت سلامتی و شرایط بالینی باعث میشود نتایج این مطالعات با هم تفاوت داشته باشند، که این همان هتروژنیتی بالینی است.
این نوع هتروژنیتی زمانی رخ میدهد که طراحی پژوهش، ابزار اندازهگیری متغیرها یا مدت زمان پیگیری در مطالعات مختلف با هم فرق داشته باشد. حتی اگر مداخله و جمعیت مشابه باشند، اختلاف در روش اجرا میتواند اختلاف آماری ایجاد کند.
برای نمونه، دو مطالعه ممکن است اثر یک برنامه ورزشی بر فشار خون را بسنجند، اما یکی فشار خون را با دستگاه دیجیتال در شرایط استراحت اندازهگیری کند و دیگری با دستگاه جیوهای پس از فعالیت. این تفاوت روش اندازهگیری میتواند منجر به اختلاف معنیدار نتایج شود، که این هتروژنیتی روششناختی است.
این نوع هتروژنیتی به اختلاف کمّی نتایج مطالعات اشاره دارد که با شاخصهای آماری اندازهگیری میشود. حتی اگر شرایط بالینی و روششناسی مشابه باشند، ممکن است نتایج عددی متفاوت باشند. به زبان ساده، حتی اگر دو مطالعه دقیقاً روی جامعه مشابه و با روش یکسان انجام شده باشند، ممکن است مقادیر برآورد اثر آنها بهطور قابل توجهی متفاوت باشد؛ این تفاوت در اعداد همان هتروژنیتی آماری است. شاخصهایی مانند آماره Q، I² و τ² برای شناسایی و اندازهگیری این اختلاف استفاده میشوند.
فرض کنید پنج مطالعه مشابه اثر یک مکمل را بررسی کردهاند، اما درصد بهبود گزارششده در آنها بین ۵ تا ۳۰ درصد متغیر است. این اختلاف عددی در نتایج، بدون در نظر گرفتن دلایل بالینی یا روششناختی، نشاندهنده هتروژنیتی آماری است.
برای محاسبه هتروژنیتی سه آماره مورد استفاده قرار می گیرد که در همه مقالات فراتحلیل دیده می شود.
برای مثال فرض کنید ۵ مطالعه اثر یک داروی ضد فشار خون را بررسی کردهاند و مقادیر کاهش فشار خون (بر حسب mmHg) به صورت زیر گزارش شده است:
با ترکیب این دادهها، متوجه میشویم که اختلاف بین عدد 5 و 15 mmHg بیش از چیزی است که از خطاهای نمونهگیری انتظار داشته باشیم. اگر شاخص I²، مثلاً 65% محاسبه شود، نشاندهنده هتروژنیتی آماری بالا است و استفاده از مدل اثرات تصادفی برای برآورد دقیقتر ضروری میشود.
هتروژنیتی، اگرچه در بسیاری از فراتحلیلها اجتنابناپذیر است، اما با روشهای آماری و تحلیلی میتوان آن را کاهش داد یا اثراتش را مدیریت کرد. هدف از مدیریت هتروژنیتی، افزایش دقت برآورد اثر ترکیبشده و جلوگیری از نتیجهگیری اشتباه است.
روشهای اصلی مدیریت ناهمگونی شامل انتخاب مدل آماری مناسب (مانند مدل اثرات تصادفی)، انجام تحلیل زیرگروهها، و استفاده از متارگرسیون برای بررسی منابع بالقوه اختلاف بین مطالعات است.
مدل اثرات تصادفی فرض میکند که مطالعات نه تنها به دلیل خطای نمونهگیری متفاوت هستند، بلکه هر مطالعه برآورد اثر واقعی متفاوتی دارد که حول یک میانگین کلی توزیع شده است. این مدل به جای فرض یک مقدار ثابت برای همه مطالعات، اختلاف بین آنها را بهعنوان بخشی از مدل لحاظ میکند و واریانس بینمطالعات (Tau-square) را در محاسبات وارد میکند.
مزیت:
برای مثال، فرض کنید در ۵ مطالعه اثر یک مکمل غذایی بر کاهش LDL کلسترول بررسی شده است و نتایج بین این مطالعات به شدت متفاوت است (کاهش ۳ تا ۲۰ mg/dL). استفاده از مدل اثرات ثابت باعث میشود نتایج مطالعات بزرگ به شدت بر نتیجه کلی غالب شوند، اما مدل اثرات تصادفی با در نظر گرفتن Tau-square برآوردی متعادلتر میدهد که تفاوتهای واقعی بین محیطها و جمعیتها را لحاظ میکند.
تحلیل زیرگروهها شامل تقسیم دادهها به گروههای کوچکتر بر اساس یک ویژگی خاص (مانند سن، جنسیت، نوع مداخله، یا منطقه جغرافیایی) و سپس انجام فراتحلیل جداگانه برای هر گروه است. این کار کمک میکند تا علت احتمالی هتروژنیتی شناسایی شود.
مزیت:
فرض کنید چند مطالعه اثر یوگا بر کاهش اضطراب را بررسی کردهاند. وقتی همه مطالعات با هم تجمیع میشوند، I² برابر ۶۰٪ است (هتروژنیتی بالا). با تقسیم مطالعات به دو زیرگروه بر اساس سن شرکتکنندگان (زیر ۴۰ سال و بالای ۴۰ سال)، مشاهده میشود که هتروژنیتی در هر زیرگروه کاهش یافته و اثر یوگا در گروه زیر ۴۰ سال بسیار بیشتر از گروه بالای ۴۰ سال بوده است. این یافته میتواند مسیر طراحی تحقیقات بعدی را مشخص کند.
متارگرسیون یک روش آماری پیشرفته برای بررسی رابطه بین ویژگیهای مطالعات (متغیرهای توضیحی یا Covariates) و اندازه اثر آنها است. در این روش، اندازه اثر مطالعات به عنوان متغیر وابسته و ویژگیهای مطالعات (مانند سال انتشار، مدت پیگیری، دوز مداخله، کیفیت مطالعه) به عنوان متغیر مستقل وارد مدل رگرسیونی میشوند.
مزیت:
برای مثال، فرض کنید ۲۰ مطالعه اثر یک داروی آرامبخش را بررسی کردهاند. شدت اثر دارو از ۱۰٪ تا ۵۰٪ کاهش اضطراب متفاوت است. با استفاده از متارگرسیون میتوان بررسی کرد که آیا دوز دارو و مدت درمان با میزان اثر ارتباط دارد یا نه. نتیجه ممکن است نشان دهد که هر چه دوز بالاتر باشد، اثر قویتر است، و هر چه مدت درمان بیشتر باشد، پایداری اثر افزایش مییابد. این تحلیل میتواند مستقیماً در بهینهسازی پروتکل درمان مورد استفاده قرار گیرد.
