

ANOVA مخلوط (Mixed ANOVA) میانگین تفاوتهای بین گروههایی را که بر روی دو «فاکتور» (متغیرهای مستقل) تقسیم شدهاند، مقایسه میکند، که در آن یکی از فاکتورها، «فاکتور درون سوژهای» (within-subjects factor) و دیگری «فاکتور بین سوژهای» (between-subjects factor) است. به عنوان مثال، ANOVA مخلوط اغلب در مطالعاتی استفاده میشود که در آن شما یک متغیر وابسته (مانند «کمر درد») را در دو یا چند نقطه زمانی اندازهگیری کردهاید. یا زمانی که همه سوژهها تحت دو یا چند وضعیت قرار گرفتهاند (به عنوان مثال، جایی که “زمان” یا “شرایط” فاکتور “درون سوژه ای” شماست. اما همچنین زمانی که سوژه های شما به دو یا چند گروه مجزا تقسیم شده اند. این گروه ها فاکتور «بین سوژه ای» شما را تشکیل می دهند.
هدف اولیه از ANOVA مخلوط این است که بفهمیم آیا تعاملی بین این دو فاکتور بر روی متغیر وابسته وجود دارد یا خیر. قبل از بحث بیشتر در این مورد، به مثال زیر نگاهی بیندازید، که طراحی مطالعه ای را که در آن از ANOVA مخلوط استفاده میشود، نشان میدهد:
فاکتور درون سوژه ای شما زمان است.
فاکتور بین سوژه ای شما شامل شرایطی است (که به عنوان درمان (treatments) نیز شناخته می شود).
تصور کنید که یک محقق می خواهد به افرادی که از کمردرد مزمن رنج می برند کمک کند تا سطح درد خود را کاهش دهند. محقق می خواهد دریابد که آیا یکی از دو روش درمانی مختلف در کاهش سطح درد در طول زمان موثرتر است یا خیر. بنابراین، متغیر وابسته “کمر درد” است، در حالی که فاکتور درون سوژه ای “زمان” و فاکتور بین سوژه ای “شرایط” است. به طور خاص، دو درمان مختلف که به عنوان “شرایط” شناخته می شوند، عبارتند از یک برنامه ماساژ (درمان A) و یک برنامه طب سوزنی (درمان B). این دو درمان منعکس کننده دو گروه فاکتور “بین سوژه ای” هستند.
در مجموع 60 شرکت کننده در این آزمایش شرکت می کنند. از این 60 شرکتکننده، 30 نفر بهطور تصادفی تحت درمان A (برنامه ماساژ) قرار میگیرند و 30 نفر دیگر درمان B (برنامه طب سوزنی) را دریافت میکنند. هر دو برنامه درمانی 8 هفته طول می کشد. در طول این دوره 8 هفته ای، کمردرد در سه نقطه زمانی اندازه گیری می شود که نشان دهنده سه گروه فاکتور “درون سوژه ای”، یعنی “زمان” سه گروه زمانی شامل: ابتدای برنامه [نقطه زمانی 1]، اواسط برنامه [نقطه زمانی 2] و انتهای برنامه [نقطه زمانی 3] می باشد.
در پایان آزمایش، محقق از یک ANOVA مخلوط استفاده میکند تا تعیین کند که آیا هرگونه تغییر در کمردرد (یعنی متغیر وابسته) نتیجه تعامل بین نوع درمان (یعنی برنامه ماساژ یا برنامه طب سوزنی؛ عبارت است از «شرایط» که فاکتور «بین سوژه ای» است) و زمان (یعنی فاکتور درون سوژه ای، متشکل از سه نقطه زمانی)است.
همانطور که در بالا ذکر شد، هدف اصلی یک ANOVA مخلوط این است که بفهمیم آیا تعاملی بین فاکتور درون سوژه ای و فاکتور بین سوژهای بر روی متغیر وابسته وجود دارد یا خیر. هنگامی که مشخص کردید که آیا یک تعامل آماری معنادار وجود دارد یا خیر، چندین رویکرد مختلف برای پیگیری نتیجه وجود دارد. باید بدانید که ANOVA مخلوط یک آزمون آماری همه جانبه است و نمی تواند به شما بگوید که کدام گروه های خاص در هر فاکتور به طور قابل توجهی با یکدیگر متفاوت هستند. برای مثال، اگر یکی از عوامل شما (به عنوان مثال، “زمان”) دارای سه گروه باشد (به عنوان مثال، سه گروه سه نقطه زمانی شما هستند: “نقطه زمانی 1″، “نقطه زمانی 2” و “نقطه زمانی 3”)، نتیجه ANOVA مخلوط نمی تواند به شما بگوید که آیا مقادیر متغیر وابسته برای یک گروه (مثلاً “نقطه زمانی 1”) در مقایسه با گروه دیگر (مثلاً “نقطه زمانی 2”) متفاوت است یا خیر. فقط به شما می گوید که حداقل دو گروه از سه گروه متفاوت بودند.
از آنجایی که ممکن است سه، چهار، پنج یا چند گروه در طراحی مطالعه خود داشته باشید، و همچنین دو فاکتور، تعیین اینکه کدام یک از این گروه ها با یکدیگر متفاوت هستند، مهم است. شما می توانید این کار را با استفاده از آزمون های تعقیبی (post hoc tests) انجام دهید، که در ادامه این آموزش به آن خواهیم پرداخت. علاوه بر این، در جایی که تعاملات آماری معنیداری یافت میشود، باید تعیین کنید که آیا «اثرات اصلی ساده» (simple main effects) وجود دارد یا خیر، و اگر وجود دارد، این تأثیرات کدام ها هستند.
اگر مطمئن نیستید که یک ANOVA مختلط مناسب است، ممکن است بخواهید تفاوت آن با یک ANOVA اندازه گیری مکرر دو طرفه را نیز در نظر بگیرید. هر دو ANOVA مختلط و ANOVA اندازه گیری های مکرر دو طرفه شامل دو فاکتور هستند. همچنین هر دو به درک اینکه آیا تعاملی بین این دو فاکتور بر روی متغیر وابسته وجود دارد یا خیر تمایل دارند. با این حال، تفاوت اساسی این است که یک ANOVA اندازهگیریهای مکرر دو طرفه دارای دو فاکتور «درون سوژهای» است، در حالی که یک ANOVA مخلوط فقط یک فاکتور «درون سوژهای» دارد، زیرا فاکتور دیگری یک فاکتور «بین سوژهای» است.
بنابراین، در یک ANOVA اندازه گیری های مکرر دو طرفه، همه سوژه ها تحت همه شرایط قرار می گیرند. به عنوان مثال، اگر مطالعه دارای دو شرایط باشد – یک کنترل و یک درمان – همه سوژه ها هم در کنترل و هم در درمان شرکت می کنند. بنابراین، برخلاف ANOVA مختلط، در یک ANOVA اندازه گیری های مکرر دو طرفه سوژهها بر اساس برخی عوامل «بین سوژهای» به گروههای مختلف تفکیک نمیشوند. بنابراین، اگر فکر می کنید که ANOVA مخلوط آزمون مورد نظر شما نیست، ممکن است بخواهید یک ANOVA اندازه گیری های مکرر دو طرفه را در نظر بگیرید.
در این آموزش، ما به شما نشان میدهیم که چگونه یک ANOVA مختلط را با آزمونهای تعقیبی با استفاده از SPSS Statistics انجام دهید، و همچنین مراحلی را که برای تفسیر نتایج این آزمون باید طی کنید. با این حال، قبل از اینکه شما را با این روش آشنا کنیم، باید فرضیات مختلفی را که دادههای شما باید رعایت کنند تا یک ANOVA مخلوط به شما یک نتیجه معتبر بدهد، بدانید. در ادامه به این فرضیات می پردازیم.
هنگامی که تصمیم میگیرید دادههای خود را با استفاده از ANOVA مختلط تجزیه و تحلیل کنید، باید بررسی کنید که آیا دادههایی که میخواهید تجزیه و تحلیل کنید، میتوانند با استفاده از یک ANOVA مختلط تجزیه و تحلیل شوند یا نه؟. زیرا تنها زمانی استفاده از ANOVA مخلوط مناسب است که داده های شما از هفت فرضی که برای یک ANOVA مخلوط برای ارائه یک نتیجه معتبر لازم است، عبور کند. با این که بررسی این هفت فرض کمی زمان بر است با این حال کار دشواری نیست.
متغیر وابسته شما باید در سطح پیوسته اندازه گیری شود (یعنی متغیرهای بازه ای یا نسبتی هستند). نمونههایی از متغیرهای پیوسته عبارتند از: زمان (اندازهگیری شده بر حسب ساعت)، هوش (اندازهگیری شده با استفاده از نمره IQ)، نمره امتحان (اندازهگیری شده از 0 تا 20)، وزن (اندازهگیری شده بر حسب کیلوگرم)، و غیره.
فاکتور درون سوژه ای شما (یعنی متغیر مستقل درون سوژه ای) باید حداقل از دو دسته بندی، «گروه های مرتبط» (related groups) یا «جفت همسان» (matched pairs) تشکیل شده باشد. “گروه های مرتبط” نشان می دهد که در هر دو گروه افراد مشابهی وجود دارد. دلیل امکان حضور داشتن سوژه های یکسان در هر گروه به این دلیل است که هر سوژه در دو نوبت بر روی یک متغیر وابسته یکسان اندازه گیری شده است، خواه این در دو “نقطه زمانی” متفاوت باشد یا اینکه تحت دو “شرط” متفاوت قرار گرفته باشد. به عنوان مثال، ممکن است عملکرد 10 نفر را در یک آزمون املا (متغیر وابسته) قبل و بعد از اینکه آنها تحت یک شکل جدید از روش آموزشی کامپیوتری برای بهبود املا قرار گرفتند (یعنی دو “نقطه زمانی” متفاوت) اندازه گیری کرده باشید. دوست دارید بدانید که آیا آموزش کامپیوتر عملکرد املایی آنها را بهبود می بخشد؟ گروه مرتبط اول شامل سوژههای ابتدای آزمایش، قبل از آموزش املای کامپیوتری، و گروه دوم مرتبط از همان سوژهها، در پایان آموزش کامپیوتری هستند.
فاکتور بین سوژه ای (یعنی متغیر مستقل فاکتور بین سوژه ای) هر کدام باید حداقل از دو گروه طبقه بندی شده و «گروه مستقل» تشکیل شده باشد. نمونه متغیرهای مستقلی که این معیار را برآورده می کنند شامل جنسیت (2 گروه: مرد یا زن)، قومیت (3 گروه: قفقازی، آفریقایی آمریکایی و اسپانیایی تبار)، سطح فعالیت بدنی (4 گروه: کم تحرک، کم، متوسط و بالا)، حرفه (4 گروه: جراح، پزشک، پرستار، دندانپزشک) و غیره.
در هیچ گروهی از فاکتور درون سوژه یا فاکتور بین سوژه شما نباید داده های پرت قابل توجهی وجود داشته باشد. داده های پرت صرفاً نقاط داده منفردی در دادههای شما هستند که از الگوی معمول پیروی نمیکنند. مشکل داده های پرت این است که می توانند تأثیر منفی بر ANOVA مخلوط داشته باشند و تفاوت بین گروه های مرتبط (اعم از افزایش یا کاهش امتیازات متغیر وابسته) را مخدوش کنند، که دقت نتایج شما را کاهش می دهد. خوشبختانه، هنگام استفاده از SPSS Statistics برای اجرای یک ANOVA مخلوط بر روی دادههای خود، میتوانید به راحتی داده های پرت احتمالی را تشخیص دهید.
متغیر وابسته شما باید تقریباً برای هر ترکیبی از گروه های دو فاکتور شما به طور نرمال توزیع شود (یعنی فاکتور درون سوژه ای و فاکتور بین سوژه ای). این کمی مشکل به نظر می رسد، با این حال به راحتی برای استفاده از SPSS Statistics آزمایش می شود. همچنین، این فرض میتواند کمی نقض شود و همچنان نتایج معتبری ارائه دهد. برای مثال، میتوانید نرمال بودن را با استفاده از آزمون نرمال بودن Shapiro-Wilk (برای «دادههای واقعی» (actual data)) یا Q-Q Plots (برای «باقیماندههای استیودنت شده» (studentized residuals)) آزمایش کنید، که هر دو روشهای سادهای در SPSS Statistics هستند.
برای هر ترکیبی از گروه های دو فاکتور شما (یعنی فاکتور درون سوژه ای و فاکتور بین سوژه ای) باید واریانس های همگنی (homogeneity of variances) وجود داشته باشد. باز هم، در حالی که این کمی مشکل به نظر می رسد، می توانید به راحتی این فرض را در SPSS Statistics با استفاده از آزمون Levene آزمایش کنید.
که به عنوان کرویت یا کروی بودن (sphericity) شناخته می شود، واریانس تفاوت بین گروه های مرتبط فاکتور درون سوژه ای برای همه گروه های فاکتور بین سوژه ای باید برابر باشد. خوشبختانه، در SPSS Statistics آزمایش اینکه آیا دادههای شما با این فرض مطابقت دارد یا خیر، آسان است.
با استفاده از SPSS Statistics می توانید فرضیات #4، #5، #6 و #7 را بررسی کنید. فقط به یاد داشته باشید که اگر آزمون های آماری را بر اساس این فرضیات به درستی اجرا نکنید، نتایجی که هنگام اجرای ANOVA مخلوط به دست می آورید ممکن است معتبر نباشند.
در بخش بعد، روش SPSS Statistics را نشان می دهیم که می توانید از آن برای انجام یک ANOVA مخلوط بر روی داده های خود استفاده کنید. ابتدا مثالی را که در این راهنما استفاده شده معرفی می کنیم.
محققی می خواست کشف کند که آیا شدت یک برنامه تمرینی ورزشی، اما با مصرف کالری برابر، بر غلظت کلسترول در یک دوره شش ماهه تأثیر دارد یا خیر. بنابراین، متغیر وابسته “غلظت کلسترول”، فاکتور درون سوژه “زمان” و فاکتور بین سوژه ای “شرایط” است.
برای این مطالعه، 60 شرکتکننده انتخاب شدند که بهطور تصادفی به سه گروه 20 نفره تقسیم شدند. هر یک از این سه گروه 20 شرکتکننده «شرایط» متفاوتی دریافت کردند: در یک گروه، شرکتکنندگان سبک زندگی بیتحرکی فعلی خود را تغییر ندادند (یعنی این گروه شماره 1 بود که گروه «کنترل» نیز نامیده میشود). در گروهی دیگر، شرکتکنندگان تحت یک برنامه تمرینی با شدت کم قرار گرفتند که 1000 کیلوکالری در هفته مصرف میکرد (یعنی این گروه شماره 2 بود که “درمان A” نیز نامیده میشود). گروه نهایی تحت یک برنامه تمرینی با شدت بالا قرار گرفتند که 1000 کیلوکالری در هفته مصرف میکرد، اما در نتیجه برای کل زمان کمتری ورزش کردند (یعنی این گروه شماره 3 بود که “درمان B” نیز نامیده میشود). تمام شرایط (یعنی کنترل، درمان A و درمان B) شش ماه طول کشید. در طول این مدت، متغیر وابسته «غلظت کلسترول» سه بار اندازهگیری شد: «در ابتدای آزمایش» (نقطه زمانی شماره 1)، «اواسط دوره شش ماهه» (نقطه زمانی شماره 2) و « در پایان آزمایش” (نقطه زمانی شماره 3). این سه نقطه زمانی (یعنی نقطه زمانی #1، نقطه زمانی #2 و نقطه زمانی #3) سه گروه فاکتور درون سوژه ای، “زمان” را نشان میدهند.
در این مثال، سه متغیر وجود دارد: (1) متغیر وابسته، غلظت کلسترول ![]() (بر حسب mmol/L) است. (2) فاکتور بین سوژه ای، گروه
(بر حسب mmol/L) است. (2) فاکتور بین سوژه ای، گروه ![]() ، با سه دسته “Control” (گروه کنترل)، “Int_1” (درمان A) و “Int_2” (درمان B). و (3) فاکتور درون سوژه ای، زمان
، با سه دسته “Control” (گروه کنترل)، “Int_1” (درمان A) و “Int_2” (درمان B). و (3) فاکتور درون سوژه ای، زمان ![]() که دارای سه دسته است: pre (ابتدایی)، mid (اواسط) و post (پایانی).
که دارای سه دسته است: pre (ابتدایی)، mid (اواسط) و post (پایانی).
غلظت کلسترول شرکت کنندگان در متغیر ![]() در ابتدای آزمایش،
در ابتدای آزمایش، ![]() در اواسط دوره شش ماهه و
در اواسط دوره شش ماهه و ![]() در پایان آزمایش ثبت شد. این سه متغیر فاکتور درون سوژه، زمان
در پایان آزمایش ثبت شد. این سه متغیر فاکتور درون سوژه، زمان ![]() را تشکیل می دهند و امتیازات درون این سه متغیر منعکس کننده متغیر وابسته، کلسترول
را تشکیل می دهند و امتیازات درون این سه متغیر منعکس کننده متغیر وابسته، کلسترول ![]() هستند. مداخلات مختلف در متغیر
هستند. مداخلات مختلف در متغیر ![]() ذخیره شد که «Control» گروه کنترل، «Int_1» آزمایش تمرینی با شدت کم و «Int_2» آزمایش تمرینی با شدت بالا است. در شرایط متغیر، محقق می خواهد بداند که آیا تعاملی بین
ذخیره شد که «Control» گروه کنترل، «Int_1» آزمایش تمرینی با شدت کم و «Int_2» آزمایش تمرینی با شدت بالا است. در شرایط متغیر، محقق می خواهد بداند که آیا تعاملی بین ![]() و
و ![]() بر روی
بر روی ![]() وجود دارد یا خیر.
وجود دارد یا خیر.
23 مرحله زیر به شما نشان می دهد که چگونه داده های خود را با استفاده از ANOVA مخلوط در SPSS Statistics تجزیه و تحلیل کنید، از جمله اینکه کدام آزمون تعقیبی (post hoc test) را انتخاب کنید تا مشخص شود که در کجا تفاوت وجود دارد. البته در صوتی که هفت فرض گفته شده در بخش قبلی، نقض نشده باشد. در پایان این 23 مرحله، توضیح می دهیم که چه نتایجی را باید از ANOVA مخلوط خود تفسیر کنید.
همانطور که در زیر نشان داده شده است، روی
Analyze > General Linear Model > Repeated Measures…
در منوی اصلی کلیک کنید:

همانطور که در زیر نشان داده شده است، با پنجره یRepeated Measures Define Factor(s) مواجه خواهید شد:

در کادر In-Subject Factor Name، factor1 را با یک نام معنادارتر برای فاکتور درون سوژه ای خود جایگزین کنید. در این مثال، آن را با نام “time” جایگزین کنید. سپس در کادر Number of Levels تعداد نقاط زمانی را وارد کنید (یعنی تعداد سطوح فاکتور درون سوژه ای). در این مثال، عدد “3” را وارد می کنیم، که نشان دهنده ![]() ،
، ![]() و
و ![]() است، همانطور که در زیر نشان داده شده است:
است، همانطور که در زیر نشان داده شده است:

بر روی دکمه Add کلیک کنید و صفحه زیر را مشاهده خواهید کرد:
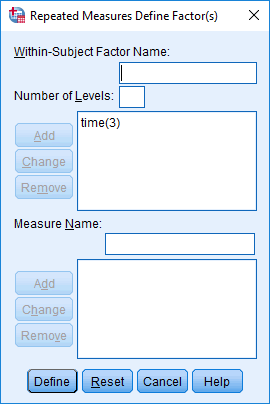
در کادر Measure Name، نامی را وارد کنید که نشان دهنده نام متغیر وابسته شما باشد. از آنجایی که متغیر وابسته ما کلسترول است، مانند شکل زیر، Cholesterol را وارد کردیم:

بر روی دکمه Add کلیک کنید و صفحه زیر را مشاهده خواهید کرد:

بر روی دکمه Define کلیک کنید و مانند شکل زیر با پنجره یRepeated Measures روبرو خواهید شد:
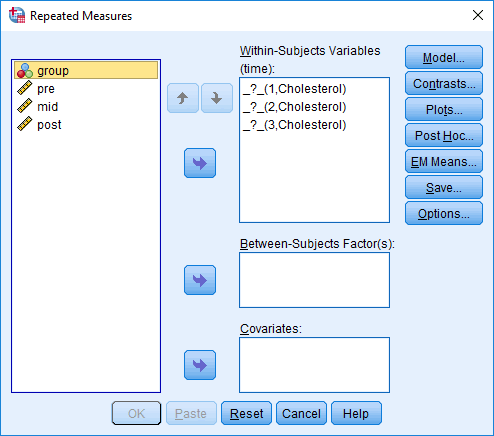
با انتخاب ![]() ،
، ![]() و
و ![]() و کلیک بر روی
و کلیک بر روی ![]() آنها را به کادر Within-Subjects Variables (time) انتقال دهید. در نهایت با صفحه زیر مواجه خواهید شد:
آنها را به کادر Within-Subjects Variables (time) انتقال دهید. در نهایت با صفحه زیر مواجه خواهید شد:
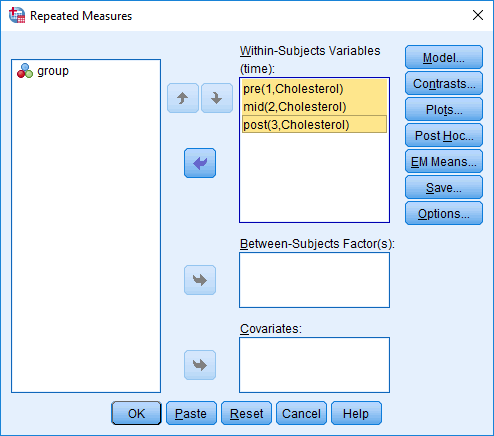
مانند شکل زیر، فاکتور بین سوژهای، ![]() ، را به کادر Between-Subjects Factor(s)، منتقل کنید:
، را به کادر Between-Subjects Factor(s)، منتقل کنید:
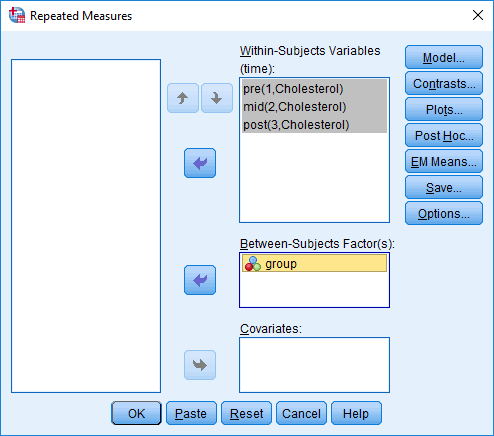
بر روی دکمه Plots کلیک کنید و مانند شکل زیر با پنجره یRepeated Measures: Profile Plots مواجه خواهید شد:
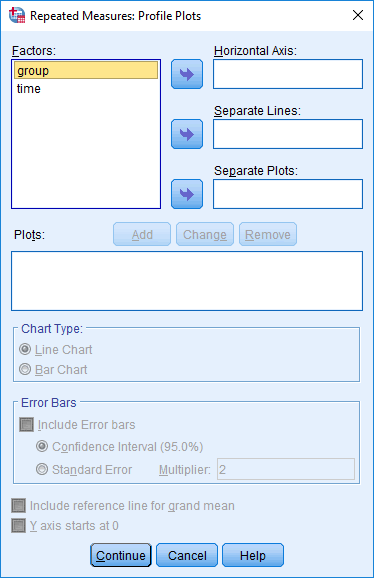
از کادر Factors، مانند شکل زیر group را به کادر Separate Lines و time را به کادر Horizontal Axis انتقال دهید:

بر روی دکمه Add کلیک کنید و این نمودار با برچسب time*group به کادر Plots اضافه می شود، همانطور که در زیر نشان داده شده است:

بر روی دکمه Continue کلیک کنید و به پنجره ی Repeated Measures باز خواهید گشت.
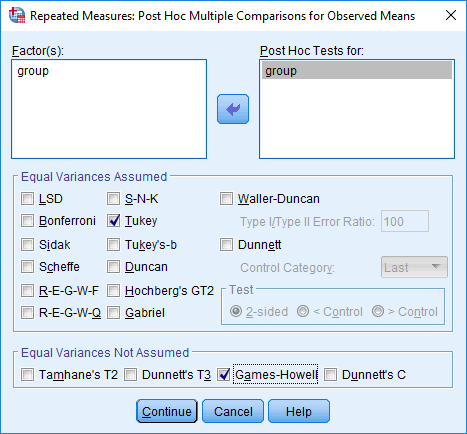
بر روی دکمه Post Hoc کلیک کنید و با پنجره یRepeated Measures: Post Hoc Multiple Comparisons for Observed Means مواجه خواهید شد، همانطور که در زیر نشان داده شده است:

Group را از کادر Factors به کادر Post Hoc Tests For انتقال دهید. همچنین، Tukey را از ناحیه –Equal Variances Assumed– و Games-Howell را از ناحیه –Equal Variance Not Assumed– انتخاب کنید. در نهایت با صفحه ای مطابق شکل زیر روبرو خواهید شد:
بر روی دکمه Continue کلیک کنید و به پنجره ی Repeated Measures باز خواهید گشت.
بر روی دکمه Save کلیک کنید و مطابق شکل زیر با پنجره ی Repeated Measures: Save مواجه خواهید شد:

مانند شکل زیر، Studentized را از ناحیه –Resideuals– انتخاب کنید:

بر روی دکمه Continue کلیک کنید و به پنجره یRepeated Measures باز خواهید گشت.
بر روی دکمه EM Means کلیک کنید و مطابق شکل زیر با پنجره یRepeated Measures: Estimated Margin Means روبرو خواهید شد:

“time”، “group” و “group*time” (اصطلاح تعامل) را از کادر Factor(s) and Factor Interactions به کادر Display Means For انتقال دهید. با این کار چک باکس Compare main effects (بررسی مقایسه اثرات اصلی) فعال میشود (یعنی دیگر خاکستری نمیشود). این کادر را علامت بزنید و Bonferroni را از منوی کشوییConfidence interval adjustment انتخاب کنید. پس از انجام تمام این کارها، با صفحه زیر روبرو خواهید شد:

بر روی دکمه Continue کلیک کنید و به پنجره یRepeated Measures باز خواهید گشت.
بر روی دکمه Options کلیک کنید و مطابق شکل زیر با پنجره یRepeated Measures: Options روبرو خواهید شد:
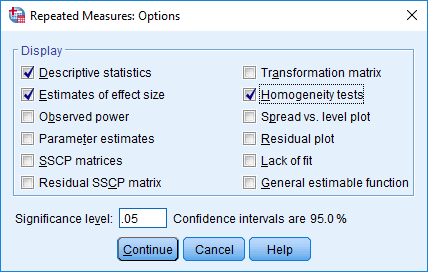
در قسمت –Display– چک باکس های Descriptive statistics,، Estimates of effect size
و Homogeneity tests را علامت بزنید، همانطور که در زیر نشان داده شده است:
بر روی دکمه Continue کلیک کنید و به پنجره یRepeated Measures باز خواهید گشت.
بر روی دکمه OK کلیک کنید. بعد از اجرای تمام مراحل گفته شده، خروجی تولید می شود.
خروجی های تولید شده توسط SPSS Statistics بسیار گسترده است و می تواند اطلاعات زیادی در مورد تجزیه و تحلیل شما ارائه دهد. با این حال، اگر یک تعامل آماری معنیدار بین دو فاکتور شما بر روی متغیر وابسته وجود داشت، باید مراحل دیگری را در SPSS Statistics انجام دهید. در زیر به طور خلاصه مراحل اصلی را توضیح می دهیم که باید برای تفسیر نتایج ANOVA مخلوط خود دنبال کنید و در صورت لزوم، تجزیه و تحلیل اضافی را در SPSS Statistics انجام دهید.
شما باید نتایج حاصل از آزمون های فرضی خود را تفسیر کنید تا مطمئن شوید که می توانید از یک ANOVA مخلوط برای تجزیه و تحلیل داده های خود استفاده کنید. این شامل تجزیه و تحلیل موارد زیر است: (الف) دادههای واقعی یا باقیماندههای استیودنت شده (studentized residuals) برای بررسی اینکه در هیچ گروهی از عوامل درونسوژه یا فاکتور بین سوژهای، داده های پرت قابل توجهی وجود ندارد (فرض شماره 4). (ب) داده های واقعی شما یا باقیمانده های استیودنت شده برای تعیین اینکه متغیر وابسته شما برای هر ترکیبی از گروه های دو فاکتور شما تقریباً به طور نرمال توزیع شده است (فرض شماره 5). (ج) واریانسهای هر ترکیبی از گروههای دو فاکتور شما برای بررسی همگنی واریانسها (فرض شماره 6). و (د) واریانس تفاوت بین تمام ترکیبات گروه های فاکتور درون سوژه ایی شما برای بررسی کرویت (فرض شماره 7).
خروجی SPSS Statistics تعیین می کند که آیا باید به ابتدای فرآیند ANOVA مخلوط برگردید تا سعی کنید داده های خود را تنظیم کنید تا بتوانید از این آزمایش استفاده کنید (به عنوان مثال، با “تبدیل” (transforming) داده های خود) . همچنین خروجی SPSS Statistics تعیین می که باید بعداً چه خروجی SPSS Statistics را تفسیر کنید (به عنوان مثال، بر اساس نتایج حاصل از آزمون کروی بودن Mauchly، که برای آزمایش فرض شماره 7 استفاده می شود).
شما باید یک قضاوت اولیه در مورد اینکه داده های شما چگونه به نظر می رسد را داشته باشید. شما می توانید این کار را با تفسیر نمودار نمایه (profile plot) انجام دهید. هنگامی که این کار را انجام دادید، می توانید به آزمون آماری رسمی در خروجی Tests of Insubjects Effects SPSS Statistics نگاهی بیندازید تا تعیین کنید که آیا واقعاً یک اصطلاح تعامل آماری معنی دار دارید یا خیر. اینکه کدام قسمت از این خروجی را باید تفسیر کنید به این بستگی دارد که آیا دادههای شما آزمونهای فرضیات مرحله شماره 1 در بالا را پشت سر گذاشتهاند یا خیر.
اگر تعامل آماری معنیداری دارید، گزارش اثرات اصلی در خروجی SPSS Statistics Tests of Insubjects Effects میتواند گمراهکننده باشد. در عوض، شما باید تفاوت بین گروه های خود را در هر سطح از هر فاکتور تعیین کنید. شما این کار را با تجزیه و تحلیل مجدد دادههای خود انجام میدهید تا مشخص کنید چه چیزی به عنوان اثرات اصلی ساده شناخته میشود (یعنی به جای اثرات اصلی). شما باید این کار را برای هر دو فاکتور انجام دهید. به عنوان مثال، با استفاده از مثال کمردرد در ابتدای این راهنما، ابتدا علاقه مند به آزمایش تأثیرات اصلی ساده فاکتور «بین افراد»، «شرایط» (یعنی این فاکتور به صورت دو گروه هستید: برنامه ماساژ و برنامه طب سوزنی). این شامل آزمایش تفاوت در مقدار کمردرد (مثلاً متغیر وابسته شما) بین دو وضعیت در هر گروه از فاکتور “درون سوژه ای”، “زمان” است. سپس باید دوباره به این کار بپردازید، اما این بار، با تمرکز بر تأثیرات اصلی ساده فاکتور درون سوژه ای خود، یعنی «زمان». پس از انجام این روشهای ساده اثرات اصلی در SPSS Statistics، باید نمودارهای نمایه تولید شده و همچنین خروجی آمار جدید SPSS را در جداول آزمون کرویت Mauchly، آزمونهای تأثیرات درون سوژه ای و مقایسههای زوجی (Pairwise Comparisons) تفسیر کنید. شما اکنون در موقعیتی هستید که می توانید تمام نتایج خود را بنویسید.
اگر تعامل آماری معنیداری ندارید، باید اثرات اصلی را در جداول خروجی SPSS Statistics Tests of Insubjects Effects تفسیر و گزارش کنید (بهعنوان مثال، به جای محاسبه اثرات اصلی ساده، که وقتی انجام میدهید تعامل از نظر آماری معنی دار است). شما باید تأثیرات اصلی را برای هر دو فاکتور تفسیر کنید (یعنی فاکتور ” درون سوژه ای” و فاکتور “بین سوژه ای”). علاوه بر این، اگر هر یک از این اثرات اصلی از نظر آماری معنیدار باشد، باید خروجی SPSS Statistics مربوطه را از آزمونهای تعقیبی خود در جدول مقایسههای زوجی تفسیر کنید. این به شما کمک می کند تا بفهمید که تفاوت بین گروه های موجود در عوامل شما کجاست (به عنوان مثال، از مثال کمردرد، تفاوت در کمردرد بین دو شرایط (برنامه ماساژ و “برنامه طب سوزنی)).
مطالب زیر را هم از دست ندهید:
ANOVA اندازه گیری های مکرر دو طرفه با استفاده از SPSS Statistics
انواع متغیر و تحقیقات تجربی و غیر تجربی
ANOVA با اندازه گیری های مکرر با استفاده از SPSS Statistics
آزمون نرمال بودن با استفاده از SPSS Statistics
ANCOVA یک طرفه در SPSS Statistics
آزمون t نمونه تکی با استفاده از SPSS Statistics
ANOVA دو طرفه در SPSS Statistics

6 پاسخ