

آزمون مک نمار(McNemar’s test) برای تعیین وجودِ تفاوت های بین دو گروه مرتبط در متغیر وابسته دو وضعیتی (dichotomous) استفاده می شود. آن را می توان شبیه آزمون t نمونه های جفت شده (paired-samples t-test) در نظر گرفت، اما به جای متغیر پیوسته باید برای یک متغیر وابسته دو وضعیتی استفاده شود. با این حال، بر خلاف آزمون t نمونههای جفت شده، میتوان آن را به عنوان آزمایش دو ویژگی متفاوت از یک متغیر دو وضعیتی اندازهگیری مکرر (repeated measure)، تصور کرد. آزمون مک نمار برای آنالیز طرحهای مطالعه پیشآزمون-پسآزمون (pretest-posttest) و همچنین معمولاً در آنالیز جفتهای همسان (matched pairs) و مطالعات موردی-شاهدی (case-control studies) استفاده میشود. اگر بیش از دو اندازه گیری تکراری دارید، می توانید از آزمون Q کوکران (Cochran’s Q) استفاده کنید.
به عنوان مثال، می توانید از آزمون مک نمار استفاده کنید تا تعیین کنید که آیا نسبت شرکت کنندگانی دارای اعتماد به نفس پایین بودند، بعد از یک سری جلسات مشاوره، میزان اعتماد به نفس آنها افزایش یافته است یا خیر؟. در اینجا متغیر وابسته “میزان اعتماد به نفس” است که دارای دو دسته “کم” و “بالا” است.
این آموزش به شما نشان میدهد که چگونه آزمون مکنمار را با استفاده از SPSS انجام دهید، و همچنین نتایج این آزمون را تفسیر و گزارش کنید. با این حال، قبل از اینکه شما را با این روش آشنا کنیم، باید فرضیات مختلفی را که طراحی مطالعه شما باید رعایت کند تا آزمون مک نمار یک انتخاب مناسب برای آزمون باشد، را باید بدانید. در ادامه به این فرضیات می پردازیم.
آزمون مک نمار دارای سه فرض است که باید رعایت شود. اگر این فرضیات برآورده نشدند، نمی توانید از آزمون مک نمار استفاده کنید، اما ممکن است بتوانید به جای آن از آزمون آماری دیگری استفاده کنید. بنابراین، برای اجرای آزمون مک نمار، باید بررسی کنید که طرح مطالعه شما با سه فرض زیر مطابقت دارد:
شما یک متغیر وابسته طبقه ای (categorical) با دو دسته (یعنی یک متغیر دو وضعیتی) و یک متغیر مستقل طبقه ای با دو گروه مرتبط دارید. نمونه هایی از متغیرهای دو وضعیتی شامل: میزان ایمنی (دو گروه: “ایمن” و “ناایمن”)، عملکرد امتحان (دو گروه: “موفق شدن” و “رد شدن”)، احساس دریازدگی (دو گروه: «بله» و «خیر»)، میزان خستگی (دو گروه: «کم» و «زیاد»)، استفاده از تجهیزات ایمنی (دو گروه: «از کلاه ایمنی استفاده میکند» و «از کلاه ایمنی استفاده نمی کند»)، اثربخشی کرم پوست (دو گروه: “بله” و “خیر”) و غیره.
دو گروه از متغیر وابسته شما باید متقابل انحصاری (mutually exclusive) باشند. این بدان معنی است که هیچ گروهی نمی تواند همپوشانی داشته باشد. به عبارت دیگر، هر شرکت کننده فقط می تواند در یکی از دو گروه باشد. آنها نمی توانند همزمان در هر دو گروه باشند. به عنوان مثال، تصور کنید که از آزمون مک نمار استفاده می کنید تا بفهمید آیا تعداد شرکت کنندگانی که امتحان را قبول شده اند (در مقابل رد شده اند) بعد از یک دوره رفع اشکال (یعنی مداخله) نسبت به قبل از مداخله، افزایش یافته است یا خیر؟. در اینجا متغیر وابسته «عملکرد امتحان» است که دارای دو دسته قبولی و مردودی است. هنگامی که یک شرکتکننده در آزمون شرکت میکرد، فقط میتوانست در آن “قبول شود” یا “مردود شود”. آنها نمی توانستند هم زمان امتحان را هم پاس کنند و هم در آن مردود شوند (مثلاً از 20 نمره، 10 و بالاتر، “پاس” بود، کمتر از 10، مردود به حساب می آمد).
موارد (cases) (به عنوان مثال، شرکت کنندگان) یک نمونه تصادفی از جامعه مورد نظر هستند. با این حال، در عمل، نمونه گیری همیشه اینطور نیست.
اگر طرح مطالعه شما این سه فرض را برآورده نکند، نمی توانید از آزمون مک نمار استفاده کنید، اما ممکن است بتوانید به جای آن از آزمون آماری دیگری استفاده کنید. با این حال، با فرض اینکه شما از آزمون درست استفاده می کنید، ما به شما نشان می دهیم که چگونه داده های خود را با استفاده از آزمون مک نمار آنالیز کنید. ابتدا شما را با مثالی که در این آموزش استفاده کرده ایم، آشنا می کنیم.
محققی می خواست تأثیر یک مداخله بر سیگار کشیدن را بررسی کند. در این مطالعه فرضی، 50 شرکت کننده شامل 25 سیگاری و 25 غیر سیگاری برای شرکت در این مطالعه انتخاب شدند. همه شرکتکنندگان یک ویدیوی را تماشا کردند که نشاندهنده تاثیر مرگومیر ناشی از سرطانهای مرتبط با سیگار بر خانوادهها بود. دو هفته پس از این مداخله ویدئویی، از همان شرکت کنندگان پرسیده شد که آیا سیگاری هستند یا نه.
بنابراین، شرکتکنندگان قبل از مداخله به عنوان سیگاری یا غیرسیگاری طبقهبندی شدند و پس از مداخله مجدداً به عنوان سیگاری یا غیرسیگاری ارزیابی شدند. با توجه به اینکه شرکت کنندگان یکسان دو بار اندازه گیری می شوند، نمونه های جفت شده داریم. ما همچنین یک متغیر وابسته داریم که دارای دو دسته دو وضعیتی (یعنی “سیگاری” (smoker) و “غیر سیگاری” (non-smoker)) است. در نتیجه، آزمون مک نمار گزینه مناسبی برای آنالیز داده ها است.
برای آزمون مک نمار، دو یا سه متغیر خواهید داشت:
(1) پاسخ های دو وضعیتی برای اولین گروه از گروه های مرتبط ( ![]() ، که نشان می دهد شرکت کنندگان قبل از تماشای ویدیو، “غیر سیگاری” یا “سیگاری” بودند).
، که نشان می دهد شرکت کنندگان قبل از تماشای ویدیو، “غیر سیگاری” یا “سیگاری” بودند).
(2) پاسخهای دو وضعیتی برای دومین گروه از گروههای مرتبط ( ![]() ، که نشان میدهد شرکتکنندگان پس از تماشای ویدیو، «غیر سیگاری» یا «سیگاری» بودند). و
، که نشان میدهد شرکتکنندگان پس از تماشای ویدیو، «غیر سیگاری» یا «سیگاری» بودند). و
(3) فراوانی (frequencies) (یعنی تعداد کل) برای چهار ترکیب ممکن جفت شده: (الف) “غیر سیگاری” قبل و بعد از مداخله. (ب) “غیر سیگاری” قبل از مداخله، اما “سیگاری” پس از مداخله. (ج) “سیگاری” قبل و بعد از مداخله. و (د) “سیگاری” قبل از مداخله، اما “غیر سیگاری” بعد از مداخله. این در متغیر ![]() ثبت شده است.
ثبت شده است.
در شکل زیر، به شما نشان میدهیم که چگونه دادههای خود را در نمای داده SPSS تنظیم میکردید: (الف) اگر دادههای خود را با استفاده از امتیازهای فردی برای هر شرکتکننده وارد کنید (individual scores for each participant) (شکل سمت چپ)، شما فقط دو متغیر دارید. (ب) اگر دادههای خود را با استفاده از داده های شمارش کل وارد کنید (total count data) (شکل سمت راست)، که به عنوان فرکانس نیز شناخته می شود، در آن شما سه متغیر دارید.

فقط به یاد داشته باشید که اگر دادههای خود را با استفاده از دادههای تعداد کل (فراوانی ها)، که در شکل سمت راست بالا نشان داده شده است، وارد کنید، باید موارد خود را نیز وزن کنید (weight your cases) تا بتوانید دادههای خود را آنالیز کنید، که یک روش در SPSS اضافی است.
سه مرحله زیر به شما نشان می دهد که چگونه داده های خود را با استفاده از آزمون مک نمار در SPSS آنالیز کنید. ما روش Legacy Dialogs > 2 Related Samples را در SPSS برای اجرای آزمون McNemar به شما نشان میدهیم، زیرا این روش، قابل استفاده با طیف گستردهای از ورژن های SPSS می باشد. با این حال، میتوانید با استفاده از روش Nonparametric Tests > Related Samples که برای ورژن های 18 تا 28 در دسترس است، آزمون مکنمار را نیز اجرا کنید. این روش آزمونهای Nonparametric Tests > Related Samples، آمار اضافی و گزینههای گرافیکی بیشتری را نسبت به روش Legacy Dialogs > 2 Related Samples مرتبط ارائه میدهد.
همانطور که در زیر نشان داده شده است، روی
Analyze > Nonparametric Tests > Legacy Dialogs > 2 Related Samples…
در منوی اصلی کلیک کنید:
همانطور که در زیر نشان داده شده است، با پنجره ی Two-Related-Samples Tests روبرو خواهید شد:

متغیرهای ![]() و
و ![]() را به کادر Test Pairs منتقل کنید.. در نهایت با صفحهای مشابه تصویر زیر مواجه خواهید شد:
را به کادر Test Pairs منتقل کنید.. در نهایت با صفحهای مشابه تصویر زیر مواجه خواهید شد:
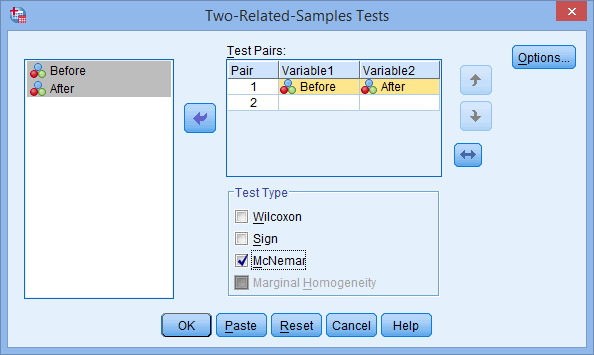
توضیح: کادر ![]() جایی است که متغیر(های) وابسته ای را که می خواهید آنالیز کنید، وارد می کنید. شما می توانید بیش از یک متغیر وابسته را به این کادر انتقال دهید تا بتوانید از متغیرهای وابسته بسیاری را به صورت همزمان آنالیز کنید.
جایی است که متغیر(های) وابسته ای را که می خواهید آنالیز کنید، وارد می کنید. شما می توانید بیش از یک متغیر وابسته را به این کادر انتقال دهید تا بتوانید از متغیرهای وابسته بسیاری را به صورت همزمان آنالیز کنید.
توجه: بهطور پیشفرض، SPSS از میزان معنیداری آماری 0.05 و فاصله اطمینان 95 درصد مربوطه استفاده میکند. این معادل با اعلام معنیدار آماری (statistical significance) در میزان p<.05 است. اگر نیاز دارید که این مقادیر را مطابق با طراحی مطالعه خود تغییر دهید (به عنوان مثال، میزان معنی داری آماری 0.01 و فاصله اطمینان 99%)، می توانید این کار را فقط با استفاده از روش جدیدتر ناپارامتریک (nonparametric) انجام دهید، که گزینه های بسیار بیشتری را نسبت به روش legacy فوق در اختیار شما قرار می دهد.
برای تولید خروجی، روی دکمه OK کلیک کنید.
اکنون که روش آزمون مک نمار را اجرا کرده اید، به شما نشان می دهیم که چگونه نتایج خود را تفسیر و گزارش کنید.
SPSS Statistics هنگام استفاده از روش Legacy Dialogs > 2 Related Samples، دو جدول خروجی اصلی را برای آزمون McNemar تولید می کند: جدول Crosstabulation و جدول Test Statistics. این جداول به نوبه خود در زیر مورد بحث قرار می گیرند:
هنگام گزارش نتیجه آزمون مک نمار، مهم است که آمار توصیفی را نیز تفسیر و گزارش کنید تا برداشتتان را از داده های خود داشته باشید و همچنین باید توصیف مناسبی از دادههای خود ارائه دهید. یکی از معیارهای مهمی که میتوانیم گزارش کنیم، نسبت شرکتکنندگانی است که هم قبل و هم بعد از مداخله غیرسیگاری بودند. همانطور که در زیر مشاهده می کنید، این در نتایج ایجاد شده در جدول Crosstabulation (که در این مثال جدول Before & After نامیده می شود) نشان داده شده است:

توجه: نام جدول از دو متغیر در آنالیز (یعنی قبل و بعد (![]() و
و ![]() )) گرفته شده است. به این ترتیب، جدول شما دارای عنوان متفاوتی خواهد بود که نام متغیرها را در آنالیز شما منعکس می کند.
)) گرفته شده است. به این ترتیب، جدول شما دارای عنوان متفاوتی خواهد بود که نام متغیرها را در آنالیز شما منعکس می کند.
ابتدا با مراجعه به سلول پایین سمت چپ، می توانید ببینید که 16 شرکت کننده در ابتدا سیگاری بودند، اما پس از مداخله (تماشای ویدیو)، غیر سیگاری شدند. به این معنا که مداخله برای کاهش مصرف سیگار طراحی شده است، این شرکت کنندگان را می توان موفقیت های مداخله در نظر گرفت. با این حال، با مراجعه به سلول بالا سمت راست، می توانید ببینید که 5 شرکت کننده غیر سیگاری بعد از مداخله، سیگار کشیدن را شروع کردند! واضح است که این اثری نیست که شما به دنبال آن بودید (اثر منفی) و مهم است که در گزارش خود به این موضوع توجه کنید. بنابراین، اگرچه به طور کلی تغییرات «مثبت» بیشتری نسبت به تغییرات «منفی» وجود داشت، با این حال دانستن «برداشت» های متفاوتی که شرکتکنندگان از دیدن ویدیو داشتند، میتواند روشنکننده باشد.
اکنون که می دانیم نسبت افراد غیر سیگاری به دنبال مداخله افزایش یافته است، می خواهیم بدانیم که آیا این تفاوت از نظر آماری معنی دار است یا خیر. برای دانستن این موضوع می توانیم از نتیجه آزمون مک نمار استفاده کنیم که در جدول Test Statistics زیر آمده است:

اگر میزان معنی داری آماری (یعنی p-value) کمتر از 0.05 باشد (یعنی p<0.05)، شما یک نتیجه آماری معنی دار دارید و نسبت افراد غیر سیگاری قبل و بعد از مداخله از نظر آماری به طور معنی داری متفاوت است. از طرف دیگر، اگر p > 0.05، نتیجه آماری معنیداری ندارید و نسبت افراد غیر سیگاری قبل و بعد از مداخله تفاوت آماری معنیداری ندارد. یعنی نسبت افراد غیر سیگاری در طول دوره مداخله تغییر نمیکند. در مثال ما 0.027 = p (با استفاده از مقدار p دقیق)، به این معنی که نسبت افراد غیر سیگاری بعد از مداخله نسبت به قبل از نظر آماری تفاوت معنیداری دارد. به عبارت دیگر، تغییر در نسبت افراد غیر سیگاری پس از مداخله از نظر آماری معنی دار بود.
توجه: متوجه خواهید شد که ما p-value دقیق را p = 0.027 گزارش کردیم (یعنی Exact Sig. (2-tailed)). وقتی آنالیز خود را انجام می دهید، ممکن است، p-value دقیق را نداشته باشید، اما در عوض یک مقدار p مجانبی (asymptotic p-value) (یعنی Asymp. Sig.) داشته باشید. این به این دلیل است که SPSS بسته به تعداد جفتهای ناسازگار (discordant pairs) در جدول Crosstabulation شما (به عنوان مثال، اولین جدول خروجی که در بالا به شما نشان دادیم) p-value را متفاوت محاسبه میکند.
با توجه به نتایج فوق، میتوان نتایج تحقیق را به شرح زیر گزارش کرد:
پنجاه شرکت کننده برای شرکت در مداخله ای که برای هشدار در مورد خطرات سیگار طراحی شده بود، استخدام شدند. یک آزمون دقیق مک نمار مشخص کرد که تفاوت آماری معنیداری در نسبت افراد غیرسیگاری قبل و بعد از مداخله وجود دارد، 0.027 = p.
توجه: اگر نتایج شما از p-value مجانبی به جای p-value دقیق استفاده میکردند، ما پیشنهاد می کنیم که خروجی را به صورت دگر گزارش کنید، تا تفاوت بین این دو مقدار در نظر گرفته شود.
تعدیل کننده دو وضعیتی (Dichotomous Moderator) با استفاده از SPSS
ضریب همبستگی تاوی- بی کندال (Kendall’s Tau-b correlation coefficient) با استفاده از SPSS
آزمون Jonckheere-Terpstra (جانكهير ترپسترا) با استفاده از SPSS
آزمون رتبه علامتدار ویلکاکسون (Wilcoxon signed-rank test) با استفاده از SPSS
آزمون Q کوکران (Cochran’s Q) با استفاده از SPSS
دی سامرز (Somers’ d) با استفاده از SPSS
آزمون t وابسته با استفاده از SPSS Statistics
آزمون t وابسته برای نمونه های جفت شده
آزمون t نمونه تکی با استفاده از SPSS Statistics
کتاب سنجی (Bibliometrics) و تفاوت آن با علم سنجی (Scientometrics) و اطلاع سنجی (Informetrics)
Afshin Safaee (@afshinsafaee.official)

7 پاسخ