

یک رگرسیون لجستیک دو جمله ای (Binomial Logistic Regression) (که اغلب به آن رگرسیون لجستیک گفته می شود)، احتمال این که یک مشاهده در یکی از دو دسته متغیر وابسته دوگانه (dichotomous) بر اساس یک یا چند متغیر مستقل پیوسته یا طبقه ای قرار می گیرد را پیش بینی می کند. از طرف دیگر، اگر متغیر وابسته شما یک عدد باشد، باید از رگرسیون پواسون (Poisson regression) استفاده کنید. از طرف دیگر، اگر بیش از دو دسته متغیر وابسته دارید، باید از رگرسیون لجستیک چند جمله ای (multinomial logistic regression) استفاده کنید.
به عنوان مثال، میتوانید از رگرسیون لجستیک دو جملهای برای درک اینکه آیا نمره امتحان را میتوان بر اساس زمان مرور درسی، اضطراب امتحان و حضور در کلاس پیشبینی کرد. در این مثال متغیر وابسته «نمره امتحان» است، که در مقیاس دوگانه «موفق شده یا شکست خورده» اندازهگیری میشود و سه متغیر مستقل “زمان مرور درسی”، “اضطراب امتحان” و “حضور در کلاس” وجود دارد.
این آموزش به شما نشان میدهد که چگونه رگرسیون لجستیک دوجملهای را با استفاده از SPSS Statistics انجام دهید، و همچنین نتایج این آزمون را تفسیر و گزارش کنید. با این حال، قبل از اینکه شما را با این روش آشنا کنیم، باید فرضیات مختلفی را که دادههای شما باید رعایت کنند تا رگرسیون لجستیک دوجملهای به شما یک نتیجه معتبر بدهد، بدانید. در ادامه به این فرضیات می پردازیم.
هنگامی که تصمیم می گیرید داده های خود را با استفاده از رگرسیون لجستیک دو جمله ای تجزیه و تحلیل کنید، باید بررسی کنید که آیا دادههای شما می توانند با استفاده از رگرسیون لجستیک دوجملهای تجزیه و تحلیل شوند یا نه؟. شما باید این کار را انجام دهید. زیرا تنها زمانی استفاده از رگرسیون لجستیک دوجملهای مناسب است که داده های شما از چهار فرضی که برای رگرسیون لجستیک دوجملهای لازم است تا یک نتیجه معتبر را به شما ارائه دهد، “عبور کند”. در عمل، بررسی این پنج فرض کمی زمان بر خواهد بود. با این حال، کار سختی نیست.
متغیر وابسته شما باید در مقیاس دوگانه اندازه گیری شود. نمونههایی از متغیرهای دوگانه عبارتند از جنسیت (دو گروه: “مرد” و “مونث”)، وجود بیماری قلبی (دو گروه: “بله” و “خیر”)، نوع شخصیت (دو گروه: “درونگرایی” یا “برونگرایی”) ، ترکیب بدن (دو گروه: “چاق” یا “غیر چاق”) و غیره. با این حال، اگر متغیر وابسته شما در مقیاس دوگانه اندازهگیری نشده باشد، بلکه یک مقیاس پیوسته باشد، باید رگرسیون چندگانه انجام دهید، در حالی که اگر متغیر وابسته شما در مقیاس ترتیبی اندازهگیری شود، رگرسیون ترتیبی نقطه شروع مناسبتری خواهد بود.
شما یک یا چند متغیر مستقل دارید که می تواند پیوسته (یعنی یک متغیر فاصله ای یا نسبتی ) یا طبقه ای (مثلاً یک متغیر ترتیبی یا اسمی) باشد. نمونههایی از متغیرهای پیوسته عبارتند از: زمان (اندازهگیری شده بر حسب ساعت)، هوش (اندازهگیری شده با استفاده از تست IQ)، نمره امتحان (اندازهگیری شده از 0 تا 20)، وزن (اندازهگیری شده بر حسب کیلوگرم)، و غیره. نمونههایی از متغیرهای ترتیبی شامل موارد لیکرت (مثلاً مقیاس 7 درجهای از «کاملاً موافقم» تا «کاملاً مخالفم»). نمونه هایی از متغیرهای اسمی شامل جنسیت (به عنوان مثال، 2 گروه: مرد و زن)، قومیت (به عنوان مثال، 3 گروه: قفقازی، آفریقایی آمریکایی و اسپانیایی)، حرفه (به عنوان مثال، 4 گروه: جراح، پزشک، پرستار، دندانپزشک)، و غیره.
مشاهدات شما باید استقلال داشته باشند و متغیر وابسته باید دارای دسته های متقابل انحصاری (mutually exclusive) و جامع (exhaustive) باشد.
باید یک رابطه خطی بین هر متغیر مستقل پیوسته و تبدیل لوجیت (Logit Transformation) متغیر وابسته وجود داشته باشد.
شما می توانید فرض شماره 4 را با استفاده از SPSS Statistics بررسی کنید. پیش از بررسی فرض شماره 4، ابتدا باید فرض های #1، #2 و #3 بررسی شوند. ما پیشنهاد می کنیم این فرضیات را با این ترتیب گفته شده آزمایش کنید زیرا نشان دهنده ترتیبی است که در آن، اگر نقض این فرض قابل اصلاح نباشد، دیگر نمی توانید از رگرسیون لجستیک دو جمله ای استفاده کنید. فقط به یاد داشته باشید که اگر آزمون های آماری را بر اساس این فرضیات به درستی اجرا نکنید، نتایجی که هنگام اجرای رگرسیون لجستیک دو جمله ای به دست می آورید ممکن است معتبر نباشند.
در بخش بعدی، ما روش SPSS Statistics را برای انجام یک رگرسیون لجستیک دو جمله ای با فرض اینکه هیچ فرضی نقض نشده است، نشان می دهیم. ابتدا مثالی را که در این آموزش استفاده شده معرفی می کنیم.
یک محقق می خواهد پیش بینی کند که آیا “بروز بیماری قلبی” را می توان بر اساس “سن”، “وزن”، “جنس” و “VO2max” پیش بینی کرد (VO2max به حداکثر ظرفیت هوازی اشاره دارد، که یک شاخص تناسب اندام و سلامتی است). برای این منظور، محقق 100 شرکتکننده را برای انجام آزمون حداکثر VO2max و همچنین ثبت سن، وزن و جنسیت خود انتخاب کرد. شرکت کنندگان همچنین از نظر وجود بیماری قلبی مورد ارزیابی قرار گرفتند. سپس یک رگرسیون لجستیک دو جمله ای برای تعیین اینکه آیا وجود بیماری قلبی را می توان از روی VO2max، سن، وزن و جنسیت پیش بینی کرد یا خیر اجرا شد. توجه: این مثال و داده ها ساختگی است.
در این مثال، شش متغیر وجود دارد: (1) heart_disease، که این است که آیا شرکت کننده بیماری قلبی دارد: “بله” یا “خیر” (یعنی متغیر وابسته). (2) VO2max، که حداکثر ظرفیت هوازی است. (3) age، که سن شرکت کننده است. (4) weight، که وزن شرکت کننده است و (5) gender، که جنسیت شرکت کننده است (یعنی متغیرهای مستقل). و (6) caseno که شماره شرکت کننده است.
توجه: از متغیر caseno برای حذف موارد (مثلاً «نقاط پرت مهم» (significant outliers)، «نقاط اهرمی بالا» (high leverage points) و «نقاط بسیار تأثیرگذار» (highly influential points)) که هنگام بررسی فرضیات شناسایی کردهاید استفاده میشود. این به طور مستقیم در محاسبات برای تجزیه و تحلیل رگرسیون لجستیک دو جمله ای استفاده نمی شود.
10 مرحله زیر به شما نشان می دهد که چگونه داده های خود را با استفاده از یک رگرسیون لجستیک دوجمله ای در SPSS Statistics تجزیه و تحلیل کنید، البته به شرطی که هیچ یک از فرضیات گفته شده در بخش قبلی، نقض نشده باشد. در پایان این 10 مرحله، ما به شما نشان می دهیم که چگونه نتایج رگرسیون لجستیک دو جمله ای خود را تفسیر کنید.
همانطور که در زیر نشان داده شده است، روی
Analyze > Regression > Binary Logistic…
در منوی اصلی کلیک کنید:

همانطور که در زیر نشان داده شده است، با پنجره ی Logistic Regression روبرو خواهید شد:

مانند شکل زیر، متغیر وابسته heart_disease را به کادر Dependent و متغیرهای مستقل age، weight، gender و VO2max را fi کادر Covariates با استفاده از دکمه های فلش ![]() ، منتقل کنید:
، منتقل کنید:
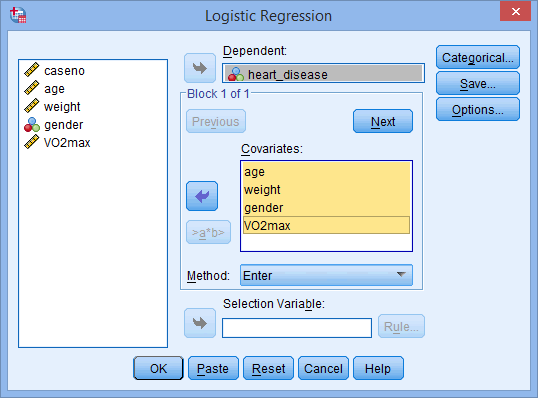
توجه: برای یک رگرسیون لجستیک استاندارد باید دکمه های ![]() و
و ![]() را نادیده بگیرید. زیرا آنها برای رگرسیون لجستیک متوالی (سلسله مراتبی) هستند. گزینه Method باید در مقدار پیش فرض یعنی Enter نگه داشته شود. اگر به هر دلیلی Enter انتخاب نشد، باید Method را به Enter تغییر دهید. روش “Enter” نامی است که توسط SPSS Statistics به تحلیل رگرسیون استاندارد داده شده است.
را نادیده بگیرید. زیرا آنها برای رگرسیون لجستیک متوالی (سلسله مراتبی) هستند. گزینه Method باید در مقدار پیش فرض یعنی Enter نگه داشته شود. اگر به هر دلیلی Enter انتخاب نشد، باید Method را به Enter تغییر دهید. روش “Enter” نامی است که توسط SPSS Statistics به تحلیل رگرسیون استاندارد داده شده است.
بر روی دکمه Categorical کلیک کنید. همانطور که در زیر نشان داده شده است، با پنجره ی Logistic Regression: Define Categorical Variables مواجه خواهید شد:
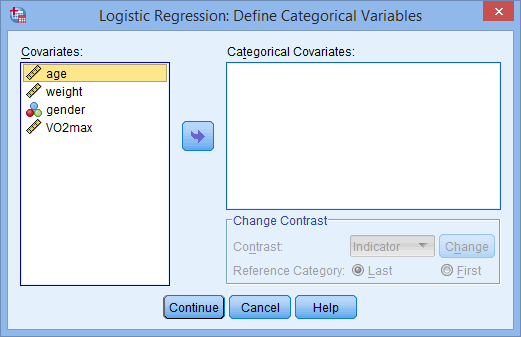
توجه: SPSS Statistics از شما می خواهد که تمام مقادیر پیش بینی کننده طبقه ای را در مدل رگرسیون لجستیک تعریف کنید. این کار به صورت خودکار انجام نمی گیرد.
مانند شکل زیر متغیر مستقل طبقه ای، gender را از کادر Covariates به کادر Categorical Covariates منتقل کنید:

Reference Category را در ناحیه Change Contrast، از گزینه Last به گزینه First تغییر دهید. سپس مطابق شکل زیر بر روی دکمه Change کلیک کنید:

توجه: اینکه گزینه Last و یا گزینه First را انتخاب کنید بستگی به نحوه تنظیم داده های شما دارد. در این مثال، مردان باید با زنان مقایسه شوند، و زنان به عنوان دسته مرجع عمل می کنند (که کد “0” بودند). بنابراین، First انتخاب شده است.
بر روی دکمه Continue کلیک کنید. شما به پنجره ی Logistic Regression بازگردانده می شوید.
بر روی دکمه Options کلیک کنید. همانطور که در زیر نشان داده شده است، با پنجره ی Logistic Regression: Options روبرو خواهید شد:
در ناحیه –Statistics and Plots–، روی گزینههای Classification plots، Hosmer-Lemeshow goodness-of-fit، Casewise listing of residuals و CI for exp(B) و در ناحیه –Display– بر روی گزینه At last step کلیک کنید. در نهایت با صفحهای مشابه تصویر زیر مواجه خواهید شد:
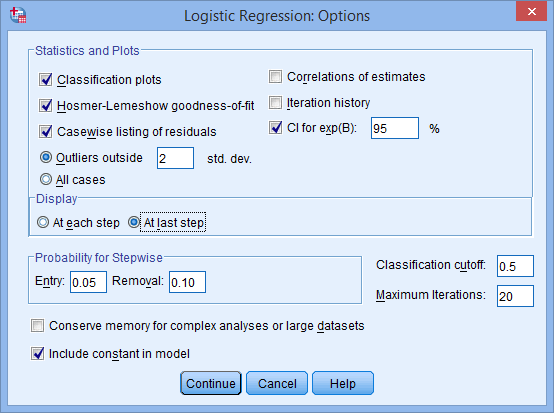
بر روی دکمه Continue کلیک کنید. شما به پنجره ی Logistic Regression بازگردانده می شوید.
بر روی دکمه OK کلیک کنید. با انجام تمام این مراحل، خروجی تولید می شود.
SPSS Statistics هنگام انجام رگرسیون لجستیک دوجمله ای جداول خروجی زیادی تولید می کند. در این بخش، ما تنها سه جدول اصلی مورد نیاز برای درک نتایج خود را از روش رگرسیون لجستیک دو جمله ای، به شرط اینکه هیچ فرض گفته شده در بخش قبل نقض نشده است، به شما نشان می دهیم.
برای اینکه بفهمید چه مقدار تغییر در متغیر وابسته را می توان با مدل توضیح داد (معادل R2 در رگرسیون چندگانه)، می توانید به جدول Model Summary، (خلاصه مدل) مراجعه کنید:

این جدول حاوی مقادیر Cox & Snell R Square و Nagelkerke R Square است که هر دو روش محاسبه تغییرات توضیح داده شده (explained variation) هستند. این مقادیر گاهی اوقات به عنوان مقادیر شبه R2 نامیده می شوند (و مقادیر کمتری نسبت به رگرسیون چندگانه خواهند داشت). با این حال، آنها به همان شیوه، اما با احتیاط بیشتر تفسیر می شوند. بنابراین، تغییرات توضیحدادهشده در متغیر وابسته بر اساس مدل ما بسته به روشهای Cox & Snell R2 یا Nagelkerke R2 به ترتیب از 24.0٪ تا 33.0٪ متغیر است. Nagelkerke R2 اصلاحی از Cox & Snell R2 است که دومی نمی تواند به مقدار 1 دست یابد. به همین دلیل، ترجیح داده می شود که مقدار Nagelkerke R2 گزارش شود.
رگرسیون لجستیک دو جمله ای احتمال وقوع یک رویداد (در این مورد، داشتن بیماری قلبی) را تخمین می زند. اگر احتمال وقوع رویداد بزرگتر یا مساوی 0.5 باشد، SPSS Statistics رویداد را به عنوان “رخ داد” طبقه بندی می کند (به عنوان مثال وجود بیماری قلبی). اگر احتمال کمتر از 0.5 باشد، SPSS Statistics رویداد را بهعنوان “رخ نداده” طبقهبندی میکند (به عنوان مثال، بدون بیماری قلبی). استفاده از رگرسیون لجستیک دو جمله ای برای پیش بینی اینکه آیا موارد را می توان به درستی از روی متغیرهای مستقل طبقه بندی کرد (یعنی پیش بینی کرد) بسیار رایج است. بنابراین، وجود روشی برای ارزیابی اثربخشی طبقهبندی پیشبینیشده در برابر طبقهبندی واقعی ضروری است. روشهای زیادی برای ارزیابی این موضوع اغلب بسته به ماهیت مطالعه انجام شده وجود دارد. با این حال، همه روشها حول طبقهبندیهای مشاهدهشده و پیشبینیشده میچرخند، که در «Classification Table» که در زیر نشان داده شده است، ارائه می گردد:
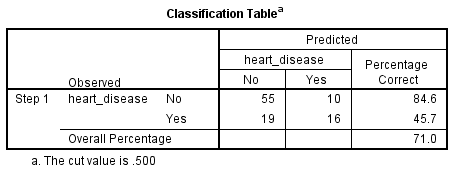
ابتدا توجه داشته باشید که جدول دارای زیرنویسی است که می گوید “مقدار برش 0.500 است” (The cut value is .500). این بدان معنی است که اگر احتمال دسته بندی یک مورد در دسته “Yes” بیشتر از 0.500 باشد، آن مورد خاص در دسته “Yes” طبقه بندی می شود. در غیر این صورت، مورد در دسته “No” (یعنی بدون بیماری قلبی) طبقه بندی می شود (همانطور که قبلا ذکر شد). جدول Classification بسیار ساده به نظر می رسد، با این حال اطلاعات مهم زیادی در مورد نتیجه رگرسیون لجستیک دو جمله ای شما ارائه می دهد، از جمله:
الف. درصد دقت در طبقهبندی (percentage accuracy in classification (PAC))، که نشاندهنده درصد مواردی است که میتوان آنها را به درستی به عنوان بیماری”بدون” قلبی با اضافه شدن متغیرهای مستقل طبقه بندی کرد
ب. حساسیت (Sensitivity)، که درصد مواردی است که دارای ویژگی مشاهده شده (به عنوان مثال، “Yes” برای بیماری قلبی) است که به درستی توسط مدل پیش بینی شده است (یعنی موارد مثبت واقعی).
ج. ویژگی (Specificity)، که درصد مواردی است که ویژگی مشاهده شده را نداشتند (مثلاً “No” برای بیماری قلبی) و همچنین به درستی به عنوان فاقد ویژگی مشاهده شده (یعنی منفی های واقعی) پیش بینی شده بودند.
د. ارزش پیش بینی مثبت (positive predictive value) که عبارت است از درصد موارد پیش بینی شده صحیح «با» مشخصه مشاهده شده در مقایسه با تعداد کل موارد پیش بینی شده دارای ویژگی.
خ. ارزش پیش بینی منفی (negative predictive value) که درصد موارد به درستی پیش بینی شده «بدون» مشخصه مشاهده شده در مقایسه با تعداد کل موارد پیش بینی شده به عنوان فاقد ویژگی است.
جدول Variables in the Equation (متغیرهای معادله) سهم هر متغیر مستقل در مدل و اهمیت آماری آن را نشان می دهد. این جدول در زیر نشان داده شده است:
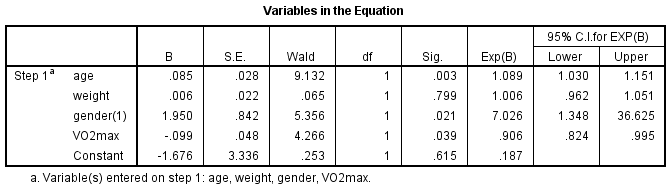
آزمون والد (ستون “Wald“) برای تعیین معناداری آماری برای هر یک از متغیرهای مستقل استفاده می شود. اهمیت آماری آزمون در ستون “Sig.” یافت می شود. این نتایج نشان می دهند که سن (003/0=p)، جنسیت (021/0=p) و VO2max (039/0=p) به طور قابلتوجهی به مدل/پیشبینی اضافه شدند، اما وزن (799/0=p) به طور قابلتوجهی به مدل اضافه نشده است. شما می توانید از اطلاعات جدول “Variables in the Equation” برای پیش بینی احتمال وقوع یک رویداد بر اساس تغییر یک واحد در یک متغیر مستقل زمانی که سایر متغیرهای مستقل ثابت نگه داشته می شوند، استفاده کنید. به عنوان مثال، جدول نشان می دهد که شانس ابتلا به بیماری قلبی (دسته “yes”) برای مردان 7.026 برابر بیشتر از زنان است.
بر اساس نتایج فوق، میتوانیم نتایج مطالعه را به شرح زیر گزارش کنیم (این شامل نتایج آزمونهای فرضیات نمیشود):
یک رگرسیون لجستیک برای تعیین اثرات سن، وزن، جنسیت و VO2max بر احتمال ابتلا به بیماری قلبی انجام شد. مدل رگرسیون لجستیک از نظر آماری معنی دار بود، χ2(4)=27.402، P<.0005. مدل 33.0% (Nagelkerke R2) از واریانس بیماری قلبی را توضیح داد و 71.0% موارد را به درستی طبقه بندی کرد. مردان 7.02 برابر بیشتر از زنان در معرض بیماری قلبی بودند. افزایش سن با افزایش احتمال بروز بیماری قلبی همراه بود، اما افزایش VO2max با کاهش احتمال بروز بیماری قلبی همراه بود.
علاوه بر نوشته بالا، گزارش شما باید موارد زیر را نیز شامل شود: (الف) نتایج آزمونهای فرضیاتی که انجام دادهاید. (ب) نتایج حاصل از ” Classification Table “، از جمله حساسیت، ویژگی، ارزش پیش بینی مثبت و منفی؛ و (ج) نتایج جدول “Variables in the Equation”، از جمله اینکه کدام یک از متغیرهای پیش بینی کننده از نظر آماری معنی دار هستند و چه پیش بینی هایی را می توان بر اساس استفاده از نسبت های شانس انجام داد. که در آینده به نحوه گزارش این موارد خواهیم پرداخت.
مطالب زیر را هم از دست ندهید:
رگرسیون پواسون با استفاده از SPSS
رگرسیون لجستیک ترتیبی با استفاده از SPSS
رگرسیون چندگانه با استفاده از SPSS
رگرسیون خطی با استفاده از SPSS
Afshin Safaee (@afshinsafaee.official)

4 پاسخ