

SPSS Statistics داده های خود را به صورت صفحه گسترده (Spreadsheet) تنظیم می کند. Spreadsheet به صفحات جدولبندی شده اطلاق میشود که قابلیت انجام محاسبات ریاضی را دارند. در اصل وارد کردن داده ها در SPSS به صورتی است که هر مورد منحصر به فرد را در یک ردیف جدید وارد کنید. مورد (case) همان “شی” (object) است که شما به نحوی در آن اندازه می گیرید. معمولا، هر مورد منحصر بفرد است، اما می تواند یک محصول تجاری یا یک سلول بیولوژیکی (یا هر چیز دیگری) باشد. برای توضیح بیشتر، فرض می کنیم که یک مورد یک فرد است. بنابراین، هنگام وارد کردن دادهها در SPSS Statistics، باید دادههای یک فرد را فقط در یک ردیف قرار دهید. اگر متوجه شدید که داده های یک فرد را در بیش از یک ردیف دارید، اشتباه کرده اید. به همین ترتیب، اگر یک ردیف حاوی داده های بیش از یک نفر باشد، شما نیز اشتباه کرده اید.
اکنون به سه کار متداول که هنگام وارد کردن دادهها در SPSS Statistics با آن روبهرو میشوید، به علاوه سه تنظیمات پیشرفتهتر را بررسی خواهیم کرد:
اگر اندازه گیری های مکرر ندارید، SPSS Statistics هر ستون را به عنوان یک متغیر جداگانه در نظر می گیرد. بنابراین، هر متغیر در یک ستون جداگانه قرار می گیرد. به عنوان مثال، اگر قد (ستون height) و وزن (ستون weight) گروهی از افراد (ستون subjects) را اندازهگیری کرده بودیم، دادههای آماری SPSS به شکل زیر خواهد بود:
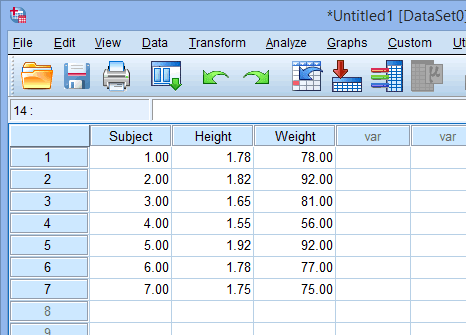
ستون Subject اضافه شده است تا مشخص شود که هر فرد در یک ردیف جداگانه قرار می گیرد. با این حال، SPSS Statistics نیازی به ورود شما به این ستون ندارد و بیشتر برای شماست که بتوانید داده های خود را بهتر تجسم کنید. بنابراین، حتی اگر ستون سوژه را نادیده بگیریم، میتوانیم ببینیم که یک فرد 1.55 متر قد و 56 کیلوگرم وزن دارد، به ترتیب به ستونهای Height و Weight نگاه میکنیم. برای اضافه کردن متغیرهای بیشتر، به سادگی ستون های بیشتری اضافه کنید – (یک ستون در هر متغیر).
معمولاً گروههای مجزا را عوامل بین سوژه ای یا گروههای مستقل مینامند. آنها گروه هایی هستند که در آن افراد در هر گروه منحصر به فرد هستند (یعنی هیچ فردی در بیش از یک گروه نیست). به این معنا، می توانید گروه ها را «متقابل انحصاری» (mutually-exclusive) بنامید. یک مثال رایج هنگام تمایز بین جنسیت است. شما می خواهید به برخی از افراد خود به عنوان زن و برخی دیگر را به عنوان مرد برچسب گذاری کنید. برای تشخیص اینکه کدام سوژهها مرد و کدام سوژهها زن بودند، باید یک «متغیر گروهبندی» در SPSS Statistics ایجاد کنید. این یک ستون جداگانه است که شامل اطلاعاتی است که یک سوژه به کدام گروه تعلق دارد. ما این کار را با برچسب گذاری عددی گروه هایمان انجام می دهیم. به عنوان مثال، ما “مرد (Male)” را به عنوان “1” و “زن (Female)” را به عنوان “2” برچسب گذاری می کنیم. با استفاده از ویژگی value میتوانیم این اعداد را به ترتیب نشاندهنده مذکر و مؤنث برچسبگذاری کنیم. یک مثال در زیر نشان داده شده است:
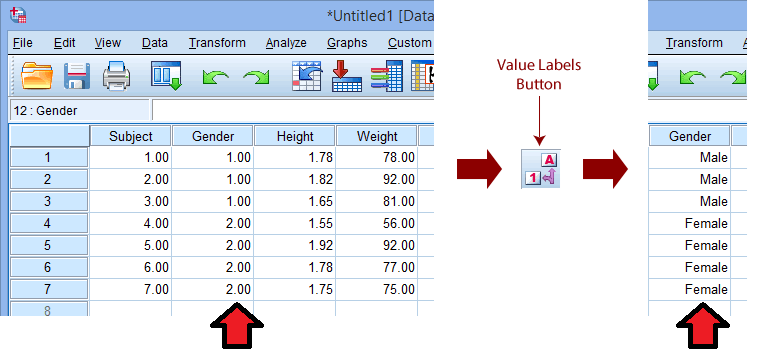
با نگاهی به ستون های سمت چپ می بینیم که یک “متغیر گروه بندی” به نام “جنسیت” (ستون Gender) ایجاد کرده ایم که دارای دو دسته است: “1” و “2”. از آنجایی که ما اعداد را با استفاده از ویژگی value برچسب گذاری کردیم، می توانیم از دکمه Value Label Button برای تغییر به نسخه متنی دسته های “متغیر گروه بندی” استفاده کنیم. در این مثال می بینیم که «1» و «2» به ترتیب با «Male» و «FeMale» جایگزین شده اند. شما نیازی به اضافه کردن برچسبهای متنی ندارید – SPSS Statistics بدون آنها به خوبی کار میکند – اما میتواند وضوح بیشتری را هنگام تجزیه و تحلیل دادههای شما ارائه دهد (مخصوصاً که از برچسبهای متنی اغلب در خروجی به جای اعداد استفاده میشود – این کمک زیادی میکند). در این مثال می بینیم که سه سوژه اول مرد و چهار سوژه آخر زن بودند. اگر بیش از دو دسته از “متغیر گروه بندی” خود داشته باشید چکار میکنید؟ ساده است، فقط اعداد بیشتری را با برچسب های متنی، موردنظر، اضافه کنید.
اندازهگیریهای مکرر که عوامل درون سوژه ای یا گروههای مرتبط نیز نامیده میشوند، متغیرهایی هستند که بیش از یک بار اندازهگیری میشوند. این می تواند زمانی رخ دهد که شما یک سوژه را برای یک متغیر در بیش از یک نقطه زمانی یا تحت بیش از یک شرط اندازه گیری کرده باشید. به عنوان مثال، شما وزن بدن را در ابتدا (Weight_Pre) و انتهای (Weight_Post) یک برنامه کاهش وزن اندازه گیری کرده اید. برای وارد کردن این مورد در SPSS Statistics، باید قانون “یک متغیر-یک ستون” را نادیده بگیرید و هر نقطه زمانی یا شرط را در یک ستون جدید به صورت زیر قرار دهید:
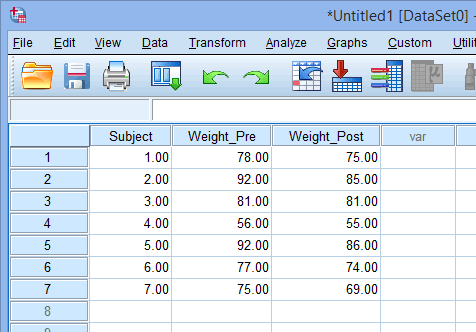
در اینجا وزن آنها را در ابتدای برنامه کاهش وزن “Weight_Pre” و وزن آنها را بعد از برنامه کاهش وزن “Weight_Post” نامگذاری کرده ایم. تا زمانی که ستونها برای شما معنی دارند، مهم نیست که این ستونهای «مرتبط» را چه مینامید (مثلاً میتوانید آنها را weight1 و weight2 بنامید). اگر زمانها و/یا شرایط زیادی دارید، برچسبگذاری منطقی متغیرها مهم است، زیرا در غیر این صورت، تعیین اینکه کدام متغیر کدام است، میتواند بسیار گیجکننده باشد. این بسیارمهم است زیرا SPSS Statistics نمی تواند تفاوت بین ستون های حاوی متغیرهای مختلف و ستون هایی که حاوی یک متغیر مکرر هستند را تشخیص دهد. بنابراین، نمی تواند به شما کمک کند.
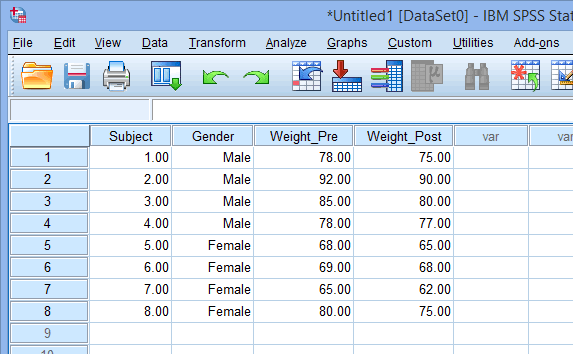
گاهی اوقات، مانند هنگام اجرای یک آنالیز ANOVA دوطرفه یا هنگام وارد کردن کل داده های مطالعه خود، باید دو بار سوژه ها را از هم جدا کنید (یعنی روی دو متغیر جداگانه). به عنوان مثال، شما باید سوژه ها را بر اساس جنسیت (مرد/ck) و سطح فعالیت بدنی آنها (بی تحرک (sedentary) / فعال (active)) از هم جدا کنید (ستون activity level). این به دو ستون نیاز دارد که به عنوان “متغیرهای گروه بندی” عمل می کنند، همانطور که در زیر نشان داده شده است:

در اینجا می بینیم که مثلاً سوژه 1 “مرد و کم تحرک” بود و سوژه 7 “زن و فعال” بود. توجه داشته باشید که ما از برچسب های متنی همانطور که قبلا در این راهنما توضیح داده شد برای وضوح بیشتر استفاده می کنیم.
گاهی اوقات، سوژهها را به گروههایی جدا کرده و سپس آنها را به طور مکرر بر روی همان متغیر وابسته اندازهگیری می کنیم. چنین داده هایی ممکن است با استفاده از یک ANOVA مختلط (mixed) تجزیه و تحلیل شوند. اگر مردان و زنان برنامه کاهش وزن را انجام میدادند و آنها را قبل و بعد از مداخله وزن کرده باشیم، تنظیمات زیر را در SPSS Statistics خواهیم داشت:
اگر داده های خود را با استفاده از رگرسیون چندگانه تجزیه و تحلیل می کنید و هر یک از متغیرهای مستقل شما در مقیاس اسمی (nominal) یا ترتیبی (ordinal) اندازه گیری شده است، باید بدانید که چگونه متغیرهای ساختگی ایجاد کنید و نتایج آنها را تفسیر کنید. این به این دلیل است که متغیرهای مستقل اسمی و ترتیبی، که بیشتر به عنوان متغیرهای مستقل طبقه بندی شناخته می شوند، نمی توانند مستقیماً وارد یک تحلیل رگرسیون چندگانه شوند. در عوض، آنها باید به متغیرهای ساختگی (dummy variables) تبدیل شوند. استثنا متغیرهای مستقل ترتیبی هستند که به عنوان متغیرهای مستقل پیوسته وارد یک رگرسیون چندگانه می شوند که نیازی به تبدیل آنها به متغیرهای ساختگی نیست. مثالی از سه متغیر ساختگی – “شنا”، “دوچرخه سواری” و “دویدن” (به ترتیب ستون های swimming،cycling و running) در نمای داده زیر برای متغیر مستقل اسمی، “ورزش_مورد علاقه” (ستون favourite_sport) نشان داده شده است.

مطالب زیر را هم از دست ندهید:
دی سامرز (Somers’ d) با استفاده از SPSS
ایجاد متغیر های ساختگی در SPSS
انواع متغیر و تحقیقات تجربی و غیر تجربی
Afshin Safaee (@afshinsafaee.official)

4 پاسخ