

آزمون t وابسته (dependent t-test) (که به آن آزمون t جفت شده (paired t-test) نیز گفته می شود) درSPSS Statistics میانگین ها را بین دو گروه مرتبط بر روی یک متغیر پیوسته و وابسته مقایسه می کند. به عنوان مثال، میتوانید از آزمون t وابسته برای درک اینکه آیا تفاوتی در مصرف روزانه سیگار سیگاریها قبل و بعد از یک برنامه هیپنوتیزم درمانی ۶ هفتهای وجود دارد یا خیر. یعنی متغیر وابسته شما «مصرف روزانه سیگار» است و دو گروه مرتبط شما مقادیر مصرف سیگار “قبل” و “بعد” از برنامه هیپنوتیزم درمانی هستند. اگر متغیر وابسته شما دوگانه (dichotomous) است، باید از آزمون مک نمار (McNemar’s test.) استفاده کنید.
این آموزش به شما نشان می دهد که چگونه یک آزمون t وابسته را با استفاده ازSPSS Statistics انجام دهید، و همچنین نتایج این آزمون را تفسیر و گزارش کنید. با این حال، قبل از اینکه شما را با این روش آشنا کنیم، باید فرضیات مختلفی را که دادههای شما باید رعایت کنند تا آزمون t وابسته به شما یک نتیجه معتبر بدهد، بدانید. در ادامه به این فرضیات می پردازیم.
هنگامی که تصمیم می گیرید داده های خود را با استفاده از آزمون t وابسته تجزیه و تحلیل کنید، ابتدا باید مطمئن شوید که داده هایی که می خواهید تجزیه و تحلیل کنید واقعاً می توانند با استفاده از آزمون t وابسته تجزیه و تحلیل شوند یا نه؟. شما باید این کار را انجام دهید. زیرا استفاده از آزمون t وابسته تنها در صورتی مناسب است که داده های شما از چهار فرض اساسی قبول شده باشد. در عمل، بررسی این چهار فرض زمان بیشتری به تجزیه و تحلیل شما میافزاید و باعث میشود کمی بیشتر در مورد دادههای خود فکر کنید. با این حال کار سختی نیست.
اگر هنگام تجزیه و تحلیل داده های خود با استفاده از SPSS Statistics ، یک یا چند مورد از این فرضیات نقض شد (یعنی برآورده نشد) تعجب نکنید. زمانی که با دادههای واقعی کار میکنید، این اتفاق عادی است. با این حال، نگران نباشید. حتی زمانی که داده های شما برخی از فرضیات را با شکست مواجه می کند، اغلب راه حلی برای غلبه بر آن وجود دارد. ابتدا اجازه دهید به این چهار فرض نگاهی بیندازیم:
متغیر وابسته شما باید در مقیاس پیوسته اندازه گیری شود (یعنی در سطح فاصله ای (interval) یا نسبتی (ratio) اندازه گیری شود). چند نمونه از متغیرهایی که این معیار را برآورده می کنند عبارتند از: مدت زمان مرور درسی (اندازه گیری شده بر حسب ساعت)، ضریب هوشی (اندازه گیری شده با استفاده از تست IQ)، نمره امتحان (اندازه گیری از 0 تا 20)، وزن (اندازه گیری شده بر حسب کیلوگرم) و غیره.
متغیر مستقل شما باید از دو طبقه بندی، گروه های وابسته (related groups) یا جفت همسان (matched pairs) تشکیل شده باشد. گروه های وابسته نشان می دهد که در هر دو گروه افراد مشابهی وجود دارد. دلیل اینکه امکان وجود موضوعات یکسان در هر گروه وجود دارد این است باید هر موضوع در دو نوبت بر روی یک متغیر وابسته اندازه گیری شود. به عنوان مثال، ممکن است شما عملکرد 10 نفر را در آزمون املا (متغیر وابسته) قبل و بعد از اینکه آنها تحت یک شکل جدید از روش آموزشی کامپیوتری برای بهبود املا قرار گرفتند، اندازه گیری کرده باشید. دوست دارید بدانید که آیا آموزش کامپیوتر عملکرد املایی آنها را بهبود می بخشد؟ گروه مرتبط اول قبل از آموزش املای کامپیوتری و گروه دوم بعد از آموزش کامپیوتری هستند. آزمون t وابسته همچنین می تواند برای مقایسه موضوعات مختلف مورد استفاده قرار گیرد، اما این اتفاق اغلب رخ نمی دهد.
در تفاوت بین دو گروه مرتبط نباید نقاط پرت قابل توجهی وجود داشته باشد. نقاط پرت صرفاً نقاط داده منفردی در دادههای شما هستند که از الگوی معمول پیروی نمیکنند (به عنوان مثال، در مطالعهای روی نمرات IQ 100 دانشآموز، که در آن میانگین نمره 108 با تفاوت کمی بین دانشآموزان بود، یک دانشآموز امتیاز 156 داشت. ، که بسیار غیرعادی است و حتی ممکن است او را در 1٪ امتیازهای IQ برتر در سطح جهان قرار دهد). مشکل پرت ها این است که می توانند تاثیر منفی بر آزمون t وابسته داشته باشند و اعتبار نتایج شما را کاهش دهند. علاوه بر این، آنها می توانند بر اهمیت آماری آزمون تأثیر بگذارند. خوشبختانه، هنگام استفاده از SPSS Statistics ، می توانید به راحتی نقاط پرت احتمالی را تشخیص دهید.
توزیع تفاوت در متغیر وابسته بین دو گروه مرتبط باید تقریباً به طور نزمال توزیع شود. ما در مورد آزمون t وابسته صحبت میکنیم که فقط به دادههای تقریباً نرمال نیاز دارد، زیرا در برابر نقض نرمال بودن کاملاً “سرسخت” است، به این معنی که این فرض میتواند کمی نقض شود و همچنان نتایج معتبری ارائه دهد. شما می توانید نرمال بودن را با استفاده از تست نرمال Shapiro-Wilk که به راحتی برای استفاده ازSPSS Statistics انجام می شود، تست کنید.
با استفاده ازSPSS Statistics می توانید فرضیات شماره 3 و 4 را بررسی کنید. قبل از انجام این کار، باید مطمئن شوید که داده های شما با فرضیات شماره 1 و 2 مطابقت دارند، اگرچه برای انجام این کار به SPSS Statistics نیاز ندارید. هنگامی که به فرضیات شماره 3 و 4 می رسیم، پیشنهاد می کنیم با ترتیب گفته شده آزمایش کنید، زیرا با این ترتیب اگر نقض فرضی قابل اصلاح نباشد، دیگر نمی توانید از آزمون t وابسته استفاده کنید (اگرچه ممکن است بتوانید به جای آن آزمایش آماری دیگری را روی داده های خود اجرا کنید). فقط به یاد داشته باشید که اگر آزمون های آماری را بر اساس این فرضیات به درستی اجرا نکنید، نتایجی که هنگام اجرای آزمون t وابسته به دست می آورید ممکن است معتبر نباشند.
در ادامه، ما روش SPSS Statistics مورد نیاز برای انجام آزمون t وابسته را با فرض اینکه هیچ فرضی نقض نشده است، نشان میدهیم. ابتدا، مثالی را که برای توضیح روش آزمون t وابسته در SPSS Statistics استفاده میکنیم، ارائه میکنیم.
گروهی از دانشآموزان علوم ورزشی (20 نفر) از بین جمعیت انتخاب میشوند تا بررسی گردند که آیا یک برنامه تمرینی پلایومتریک (plyometric-training) 12 هفتهای، عملکرد پرش بلند ایستاده (standing long jump) آنها را بهبود میبخشد یا خیر؟. در اینجا متغیر وابسته «عملکرد پرش بلند ایستاده» است و دو گروه مرتبط مقادیر پرش طول ایستاده «قبل» و «بعد از» برنامه 12 هفتهای تمرین پلایومتریک هستند.
شش مرحله زیر به شما نشان می دهد که چگونه داده های خود را با استفاده از آزمون t وابسته در SPSS Statistics تجزیه و تحلیل کنید، البته در صورتی که چهار فرض گفته شده، نقض نشده باشند. در پایان این شش مرحله، نحوه تفسیر نتایج این آزمون را به شما نشان می دهیم.
همانطور که در زیر نشان داده شده است، روی
Analyze > Compare Means > Paired-Samples T Test…
در منوی اصلی کلیک کنید:
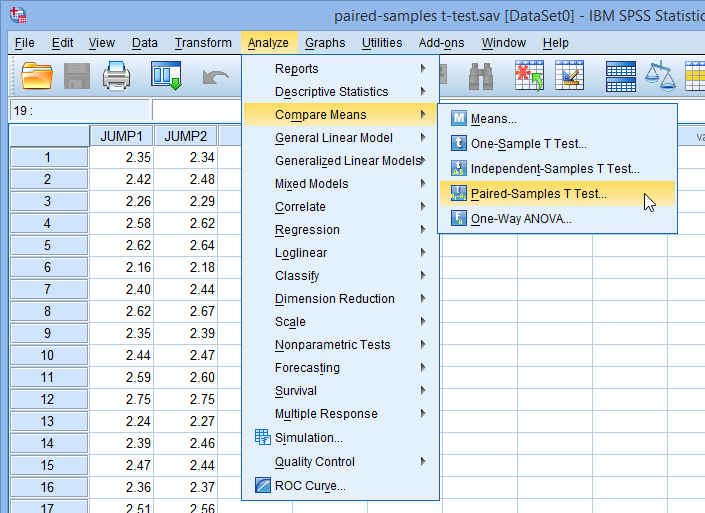
همانطور که در زیر نشان داده شده است پنجره Paired-Samples T Test نمایش داده می شود:

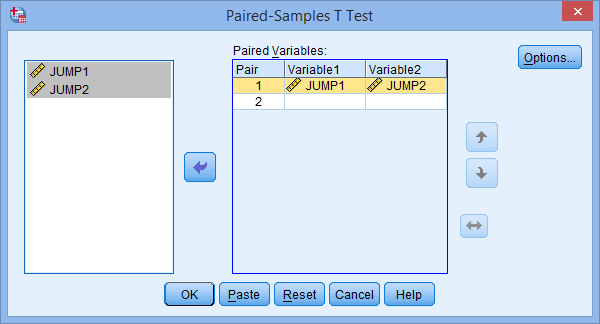
متغیرهای JUMP1 و JUMP2 را به کادر Paired Variables منتقل کنید. دو راه برای انجام این کار وجود دارد: (الف) روی هر دو متغیر کلیک کنید در حالی که کلید shift را نگه دارید (که آنها را برجسته می کند) و سپس دکمه فلش سمت راست ![]() را فشار دهید. یا (ب) هر متغیر را به طور جداگانه در کادرها بکشید و رها کنید. در نهایت با صفحه نمایشی مشابه تصویر زیر مواجه خواهید شد:
را فشار دهید. یا (ب) هر متغیر را به طور جداگانه در کادرها بکشید و رها کنید. در نهایت با صفحه نمایشی مشابه تصویر زیر مواجه خواهید شد:
توجه:
دکمه ![]() جفت متغیرهایی را که برجسته کرده اید یک ردیف به پایین جابجا می کند.
جفت متغیرهایی را که برجسته کرده اید یک ردیف به پایین جابجا می کند.
دکمه ![]() جفت متغیرهایی را که برجسته کرده اید یک ردیف به بالا تغییر می دهد.
جفت متغیرهایی را که برجسته کرده اید یک ردیف به بالا تغییر می دهد.
دکمه ![]() ترتیب متغیرها را در یک جفت متغیر، تغییر می دهد.
ترتیب متغیرها را در یک جفت متغیر، تغییر می دهد.
اگر میخواهید محدودیتهای سطح اطمینان را تغییر دهید یا موارد را حذف کنید، روی دکمه ![]() کلیک کنید. همانطور که در زیر نشان داده شده است، پنجره Paired-Samples T Test: Options نمایش داده می شود:
کلیک کنید. همانطور که در زیر نشان داده شده است، پنجره Paired-Samples T Test: Options نمایش داده می شود:
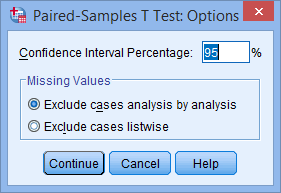
بر روی دکمه Continue کلیک کنید. شما به پنجره Paired-Samples T Test بازگردانده می شوید.
بر روی دکمه OK کلیک کنید.
SPSS Statistics سه جدول را در Output Viewer تحت عنوان “T-Test” تولید می کند، اما شما فقط باید به دو جدول نگاه کنید: جدول آماری نمونه های جفت شده و جدول تست نمونه های جفت شده. علاوه بر این، برای تعیین اینکه آیا توزیع تفاوت ها در متغیر وابسته بین دو گروه مرتبط نرمال است یا خیر، شما باید نمودارهای جعبه ای (boxplot) را که ایجاد کرده اید برای بررسی نقاط پرت و خروجی آزمون Shapiro-Wilk برای نرمال بودن تفسیر کنید. در این آموزش، ما بر روی دو جدول اصلی تمرکز میکنیم که نشان میدهد که آیا دادههای شما تمام فرضیات لازم را برآورده کردهاند یا خیر:
جدول اول با عنوان آمار نمونه های جفت شده (Paired Samples Statistics)، جایی است که SPSS Statistics آمار توصیفی را برای متغیرهای شما تولید کرده است. می توانید از نتایج اینجا برای توصیف ویژگی های JUMP1 و JUMP2 استفاده کنید.

جدول تست نمونه های جفت شده (Paired Samples Test) جایی است که نتایج آزمون t وابسته ارائه می شود. اطلاعات زیادی در اینجا ارائه شده است و مهم است که به خاطر داشته باشید که این اطلاعات به تفاوت های بین دو پرش JUMP1 و JUMP2 اشاره دارد (Paired Differences). به این ترتیب، ستونهای جدول با برچسب (Mean)، (Std. Deviation)، (Std. Error Mean) و (95% Confidence Interval of the Difference) به ترتیب به تفاوت میانگین بین دو پرش و انحراف استاندارد، خطای استاندارد و اختلاف فاصله اطمینان ۹۵ درصدی اشاره دارد. سه ستون آخر یعنی (t) t-value ، (df) درجات آزادی و (Sig. (2-tailed)) سطح معنی داری را بیان می کند.

در اینجا شما اساساً در حال انجام یک آزمون t تک نمونه ای در مورد تفاوت بین گروه ها هستید.
شما می توانید آمار را در قالب زیر گزارش دهید:
t(degrees of freedom) = t-value, p = significance level
) t درجات آزادی) = t-value، p = سطح معنی داری.
در مثال ما به این صورت خواهد بود:
![]()
با توجه به میانگین دو پرش و منفی بودن t-value، میتوان نتیجه گرفت که از نظر آماری بهبود معنیداری در فاصله پرش پس از برنامه تمرینی پلایومتریک از 0.16 ± 2.48 متر به 0.16 ± 2.52 متر وجود دارد (p<0.0005) حدود 0.03 ± 0.03 متر بهبود.
توجه: SPSS Statistics میتواند نتایج را با رقمهای اعشاری زیادی ارائه دهد، اما شما باید گزارش نتایج خود را با دقت مقیاس اندازهگیری تطبیق دهید.
همچنین شایان ذکر است که انتظار می رود که شما علاوه بر گزارش نتایج از فرضیات و آزمون t وابسته، به طور اندازه اثر (effect sizes) را نیز گزارش دهید. اندازه اثر مهم است زیرا در حالی که آزمون t وابسته به شما می گوید که آیا تفاوت بین میانگین های گروه “واقعی” است (یعنی در جامعه متفاوت است)، اما “اندازه” تفاوت را به شما نمی گوید. ارائه اندازه اثر در نتایج به غلبه بر این محدودیت کمک می کند.
مطالب زیر را هم از دست ندهید:
آزمون t وابسته برای نمونه های جفت شده

7 پاسخ