

آزمون فریدمن (Friedman Test) جایگزین غیر پارامتری برای ANOVA یک طرفه با اندازه گیری های مکرر (one-way ANOVA with repeated measures) است. از آن برای بررسی اختلاف بین گروه هایی که در آن که متغیر وابسته در حال اندازه گیری است، استفاده می شود. همچنین زمانی که از داده های پیوسته استفاده می کنید و فرضیات لازم برای اجرای ANOVA یک طرفه را با اندازه گیری های مکرر دچار نقض شده باشند (به عنوان مثال، داده ها توزیع نرمال نداشته باشند)، می توانید از آزمون فریدمن استفاده کنید.
هنگامی که مخواهید داده های خود را با استفاده از آزمون فریدمن تجزیه و تحلیل کنید، ابتدا باید اطمینان حاصل کنید که داده های شما با استفاده از این آزمون، قابل آنالیز هستند. شما باید این کار را انجام دهید زیرا فقط در صورت مطابقت داده های شما با این چهار فرض زیر، استفاده از آزمون فریدمن مناسب خواهد بود:
یک گروه که در سه یا بیشتر از سه موقعیت (occasions) مختلف اندازه گیری می شود.
گروه، نمونه ای تصادفی از جمعیت است.
متغیر وابسته شما باید در سطح ترتیبی (ordinal) یا پیوسته (continuous) اندازه گیری شود. نمونه ای از متغیرهای ترتیبی شامل مقیاس لیکرت (به عنوان مثال، مقیاس 7 نقطه ای از کاملاً موافق تا به شدت مخالف) می باشد. نمونه هایی از متغیرهای پیوسته شامل زمان، هوش (اندازه گیری شده با استفاده از نمره ضریب هوشی)، نمره امتحان (اندازه گیری از 0 تا 20)، وزن (اندازه گیری شده برحسب کیلوگرم) و غیره می باشد.
نمونه ها نیازی به توزیع عادی ندارند.
SPSS Statistics نمی تواند هیچ یک از فرضیاتی که برای آزمون فریدمن لازم است را بررسی کند. چون فرضیات این آزمون به طراحی مطالعه بستگی دارند.
یک محقق می خواهد بررسی کند که آیا پخش موسیقی بر میزان سختی درک شده در حین انجام تمرینات ورزشی تأثیر دارد یا خیر. در این مثال متغیر وابسته “میزان سختی درک شده در حین انجام تمرینات ورزشی” و متغیر مستقل “نوع موسیقی” است که از سه گروه “بدون موسیقی”، “موسیقی کلاسیک” و “موسیقی شاد” تشکیل شده است. برای بررسی اینکه آیا موسیقی در انجام تمرینات ورزشی تأثیر دارد، محقق 12 دونده را استخدام کرد که هر یک سه بار به مدت 30 دقیقه روی تردمیل دویدند. سرعت تردمیل برای هر سه اجرا یکسان بود. به ترتیب تصادفی، عملکرده هر دونده در سه حال زیر بررسی شد
(الف) بدون گوش دادن به موسیقی (none)
(ب) با گوش دادن به موسیقی کلاسیک (classical)
(ج) با گوش دادن به موسیقی شاد (dance)
در پایان هر اجرا، از افراد خواسته شد که احساس خود از دویدن را در مقیاس 1 تا 10 امتیاز بندی کنند که امتیاز 1 بسیار آسان و امتیاز 10 بسیار سخت است. سپس آزمون فریدمن انجام شد تا ببیند آیا بر اساس نوع موسیقی تفاوت هایی در سختی درک شده وجود دارد یا خیر.
SPSS Statistics تمام داده های اندازه گیری های مکرر را در همان ردیف در Data View قرار می دهد. بنابراین، شما به همان تعداد متغیرهای مربوط به گروه های مرتبط نیاز خواهید داشت. به عنوان مثال، ما به سه متغیر نیاز داریم که ما آن را “none”، “classical” و “dance” نامگذاری کرده ایم تا سختی درک شده افراد هنگام تمرین ورزشی را بر اساس سه نوع موسیقی مختلف نشان دهیم.

8 مرحله زیر به شما نشان می دهد که چگونه می توانید داده های خود را با استفاده از آزمون فریدمن در SPSS Statistics تجزیه و تحلیل کنید. در پایان این چهار مرحله، ما به شما نشان می دهیم که چگونه می توانید نتایج این آزمون را تفسیر کنید.
توجه: ما روش Legacy Dialogs > K Related Samples را برای اجرای این آزمون به شما نشان می دهیم .زیرا این روش می تواند برای طیف گسترده ای از ورژن های SPSS Statistics استفاده شود. با این حال، شما می توانید آزمون فریدمن را با استفاده از روش Nonparametric Tests > Related Samples، که برای ورژن های 18 تا 28 SPSS Statistics در دسترس است، اجرا کنید. این روش Nonparametric Tests > Related Samples، آمار اضافی و گزینه های گرافیکی بیشتری نسبت روش Legacy Dialogs > K Related Samples ارائه می دهد.
همانطور که در زیر آمده است در منوی اصلی روی
Analyze > Nonparametric Tests > Legacy Dialogs > K Related Samples..
کلیک کنید:
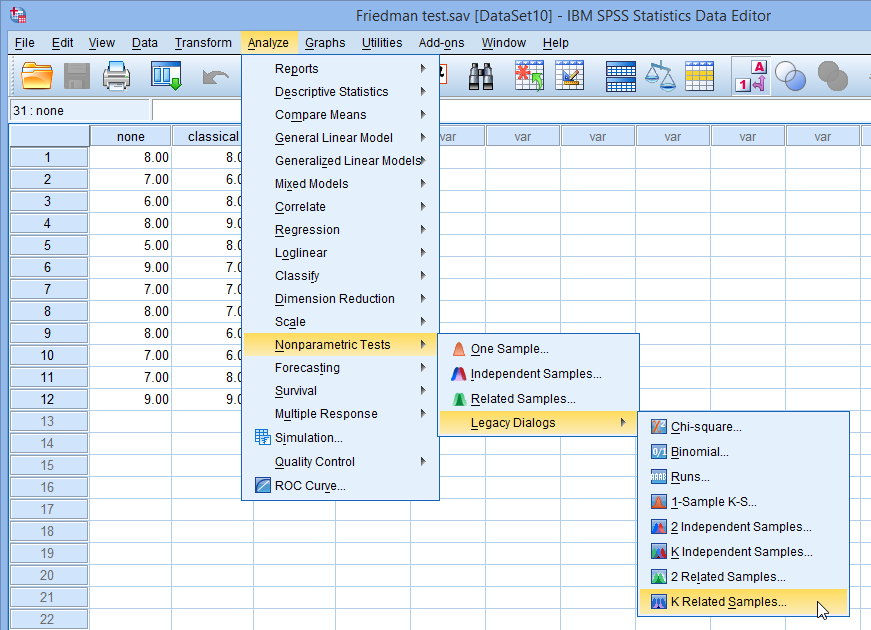
همانطور که در شکل زیر نشان داده شده است، برای چندین پنجره ی Tests for Several Related Samples نمایش داده می شود:
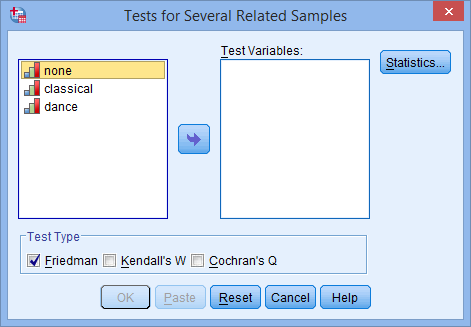
با استفاده از دکمه فلش ![]() متغیرهای none، classical و dance را به Test Variables منتقل کنید. شما در پایان با صفحه ای مانند زیر مواجه خواهید شد:
متغیرهای none، classical و dance را به Test Variables منتقل کنید. شما در پایان با صفحه ای مانند زیر مواجه خواهید شد:
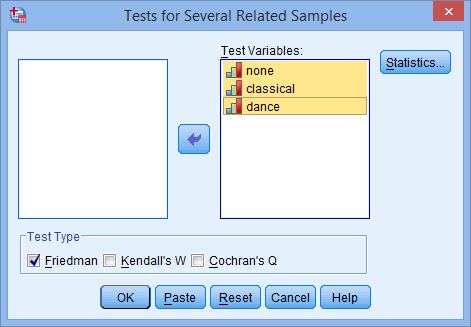
اطمینان حاصل کنید که Friedman در ناحیه Test Type انتخاب شده باشد.
روی دکمه Statistics کلیک کنید. همانطور که در شکل زیر نشان داده شده است، شما با پنجره Several Related Samples: Statistics مواجه می شوید:
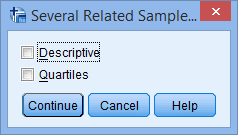
گزینه Quartiles را تیک بزنید:
توجه: بهتر است فقط گزینه Quartiles را انتخاب کنید چون شما در حال اجرای ناپارامتریک هستید و احتمالاً Descriptives برای داده های شما مناسب نیست. به هر حال SPSS Statistics این گزینه را هم نشان می دهد.
روی دکمه Continue کلیک کنید. همانطور که در زیر آمده است، با این کار شما به پنجره ی Tests for Several Related Samples باز گردانده می شوید:
برای اجرای آزمون فریدمن بر روی دکمه OK کلیک کنید.
SPSS Statistics بسته به اینکه شما کدام یک از گزینه های descriptives و quartiles انتخاب کرده اید، دو یا سه جدول ایجاد می کند.
در صورت انتخاب گزینه quartiles، جدول آمار توصیفی تولید می شود:
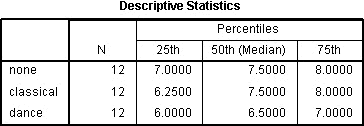
این یک جدول بسیار مفید است زیرا می تواند برای ارائه آمار توصیفی در بخش نتایج شما برای هر یک از نقاط یا شرایط زمانی (بسته به طراحی مطالعه شما) برای متغیر وابسته خود استفاده شود. این سودمندی بعداً در بخش “گزارش خروجی” ارائه می شود.
همانطور که در زیر آمده است، جدول Ranks میانگین رتبه برای هر یک از گروه های مرتبط را نشان می دهد:

آزمون فریدمن میانگین رتبه ها را بین گروه های مرتبط مقایسه می کند و چگونگی تفاوت گروه ها را نشان می دهد. به احتمال زیاد شما این مقادیر را در بخش نتایج خود گزارش نمی کنید، با این حال به احتمال زیاد مقدار میانگین را برای هر گروه مرتبط گزارش خواهید کرد.
جدول Test Statistics شما را از نتیجه واقعی آزمون فریدمن مطلع می کند، و احتمال وجود تفاوت معنی داری آماری را بین میانگین رتبه های گروه های مرتبط شما را نشان می دهد. برای مثال مورد استفاده در این آموزش، جدول به شرح زیر است:

در جدول بالا، همه چیزی که ما برای گزارش نتیجه گیری آزمون فریدمن به آن نیاز داریم، از قبیل: آمار آزمون (χ2) مقدار (“chi-square”)، درجه آزادی (“df”) و سطح معنی داری (“asymp. Sig.”) را ارائه می دهد. در این مثال، می توانیم ببینیم که از نظر آماری کلی بین میانگین رتبه های گروه های مرتبط تفاوت معنی داری وجود دارد. توجه به این نکته حائز اهمیت است که آزمون فریدمن مانند جایگزین پارامتری آن، یک آزمون Omnibus (کلینگر) است. یعنی به شما می گوید که آیا تفاوت های کلی وجود دارد یا نه؟. اما مشخص نمی کند که کدام گروه ها به طور خاص با یکدیگر متفاوت هستند. برای مشاهده این تفاوت ها باید آزمون های تعقیبی (post hoc tests) را اجرا کنید، که در بخش بعدی مورد بحث قرار خواهد گرفت.
می توانید نتیجه آزمون فریدمن را به شرح زیر گزارش کنید:
از نظر آماری تفاوت معنی داری بر میزان سختی درک شده در حین انجام تمرینات ورزشی برای نوع موسیقی گوش داده شده در در حین اجرا، وجود داشت.
χ2 (2) = 7.600 ، P = 0.022
شما همچنین می توانید مقادیر میانگین را برای هر یک از گروه های مرتبط درج کنید. با این حال، در این مرحله، شما فقط می دانید که در جایی بین گروه های مرتبط تفاوت هایی وجود دارد، اما شما دقیقاً نمی دانید که این اختلافات در کجا قرار دارد. به یاد داشته باشید که اگر نتیجه آزمون فریدمن از نظر آماری معنی دار نبود، نیازی نیست آزمون های تعقیبی را انجام دهید.
برای بررسی اینکه در واقع اختلافات در کجا رخ می دهد، باید آزمون های جداگانه Wilcoxon را در ترکیب های مختلف گروه های مرتبط انجام دهید. بنابراین، در این مثال، باید ترکیبات زیر را با یکدیگر مقایسه کنید:
None به Classical
None به Dance
Classical به Dance
شما باید از تنظیم Bonferroni در نتایج حاصل از آزمون های Wilcoxon استفاده کنید زیرا شما در حال انجام چندین مقایسه هستید، که این احتمال را افزایش می دهد که شما یک نتیجه مهم را در زمان که نباید اعلام کنید (خطای نوع I)، اعلام می کنید. خوشبختانه، تنظیم Bonferroni بسیار آسان است. به سادگی از سطح معنی داری که در ابتدا استفاده کرده اید (در این حالت، 0.05) و آن را بر اساس تعداد آزمون هایی که انجام می دهید تقسیم کنید. بنابراین در این مثال، ما سطح معنی داری جدیدی از 0.05/3=0.017 داریم. این بدان معنی است که اگر مقدار p از 0.017 بزرگتر باشد، ما نتیجه آماری معنی داری نداریم.
اجرای این آزمون ها در مورد این مثال، نتایج زیر را نشان می دهد:

این جدول خروجی آزمون رتبه علامتدار ویلکاکسون (Wilcoxon signed-rank test) را در هر یک از ترکیبات ما نشان می دهد. توجه به این نکته حائز اهمیت است که مقادیر معنی داری در SPSS Statistics برای جبران مقایسه های متعدد تنظیم نشده است. شما باید به صورت دستی مقادیر معنی داری تولید شده توسط SPSS Statistics را با سطح معنی داری تنظیم شده Bonferroni که محاسبه کرده اید مقایسه کنید. ما می توانیم ببینیم که میزان سختی درک شده در حین انجام تمرینات ورزشی برای ترکیب بدون موسیقی (none) و موسیقی شاد (dance) در سطح معنی داری p <0.017 از نظر آماری تفاوت معنی داری داشت.
شما می توانید آزمون فریدمن را با نتایج آزمون های تعقیبی به شرح زیر گزارش دهید:
بسته به اینکه نوع موسیقی در حین اجرای تمرینات ورزشی گوش داده شده است از نظر آماری تفاوت معنی داری در سختی درک شده برای انجام تمرینات وجود دارد (χ2 (2) = 7.600، P = 0.022). آزمون تعقیبی پس از آزمون رتبه علامتدار ویلکاکسون با تصحیح Bonferroni اعمال شد. سطح معنی داری در p<0.017 تعیین شد. میانه (IQR) سطح سختی درک شده را برای بررسی های بدون موسیقی، با موسیقی کلاسیک و موسیقی شاد در حال اجرا به ترتیب 7.5 (7 تا 8)، 7.5 (6.25 تا 8) و 6.5 (6 تا 7) بود. علیرغم کاهش کلی سختی درک شده برای موسیقی شاد در مقابل موسیقی کلاسیک، تفاوت معنی داری بین بررسی های بدون موسیقی و موسیقی کلاسیک (Z = -0.061، P = 0.952) یا بین بررسی های موسیقی کلاسیک و موسیقی شاد (Z = -1.811، P = 0.070) وجود نداشت. با این حال، از نظر آماری کاهش معنی داری در سختی درک شده در موسیقی شاد در مقابل بدون موسیقی وجود دارد (Z = -2.636، P = 0.008).
مطالب زیر را هم از دست ندهید:
ضریب همبستگی رتبهای اسپیرمن (Spearman rank-order correlation coefficient) با استفاده از SPSS
آزمون H کروسکال-والیس (H Kruskal-Wallis) با استفاده از Stata
MANOVA یک طرفه با استفاده از Stata
رسم نمودار پراکندگی (نقطه ای) (Scatterplot) با استفاده از SPSS
ایجاد نمودار میله ای خوشه ای (Clustered Bar Chart) با استفاده از SPSS
ANCOVA یک طرفه در SPSS Statistics
ANOVA اندازه گیری های مکرر دو طرفه با استفاده از SPSS Statistics
ANOVA با اندازه گیری های مکرر با استفاده از SPSS Statistics
ANOVA دو طرفه در SPSS Statistics
ANOVA مخلوط با استفاده از SPSS Statistics
انواع متغیر و تحقیقات تجربی و غیر تجربی
ایجاد متغیر های ساختگی در SPSS
آزمون Jonckheere-Terpstra (جانكهير ترپسترا) با استفاده از SPSS
آزمون Q کوکران (Cochran’s Q) با استفاده از SPSS
آزمون t نمونه تکی با استفاده از SPSS Statistics
آزمون t وابسته با استفاده از SPSS
آزمون t وابسته برای نمونه های جفت شده
آزمون رتبه علامتدار ویلکاکسون (Wilcoxon signed-rank test) با استفاده از SPSS
آزمون مربع کای (Chi-Square) با استفاده از SPSS
آزمون مک نمار (McNemar’s test) با استفاده از SPSS
آزمون نرمال بودن با استفاده از SPSS Statistics
آزمون یو من ویتنی (Mann-Whitney U) با استفاده از SPSS
آمار توصیفی (descriptive) و استنباطی (inferential)
آنالیز اجزای اصلی (PCA) با استفاده از SPSS
تعدیل کننده دو وضعیتی (Dichotomous Moderator) با استفاده از SPSS
دی سامرز (Somers’ d) با استفاده از SPSS
رگرسیون پواسون با استفاده از SPSS
رگرسیون چندگانه با استفاده از SPSS
رگرسیون خطی با استفاده از SPSS
رگرسیون لجستیک ترتیبی با استفاده از SPSS
رگرسیون لجستیک چند جمله ای در SPSS
رگرسیون لجستیک دو جمله ای با استفاده از SPSS
ضریب همبستگی تاوی- بی کندال (Kendall’s Tau-b correlation coefficient) با استفاده از SPSS
گامای گودمن و کروسکال (Goodman and Kruskal’s gamma) با استفاده از SPSS
