

آزمون t مستقل (independent t-test) میانگین ها را بین دو گروه غیرمرتبط بر روی یک متغیر پیوسته و وابسته مقایسه می کند. به عنوان مثال، می توانید از آزمون t مستقل برای درک اینکه آیا حقوق سال اول کارمندان دولتی بر اساس جنسیت متفاوت است یا خیر استفاده کنید (یعنی متغیر وابسته شما «حقوق کارمندان سال اولی» و متغیر مستقل شما «جنسیت» است که دو گروه دارد. : “مرد و زن”). همچنین، میتوانید از آزمون t مستقل برای درک اینکه آیا تفاوتی در اضطراب امتحان بر اساس سطح تحصیلات وجود دارد یا نه استفاده کنید (یعنی متغیر وابسته شما «اضطراب امتحان» و متغیر مستقل شما «سطح تحصیلی» است که دارای چهار گروه “کاردانی”، “کارشناسی”، “فوق لیسانس” و “دکتری” است).
این آموزش به شما نشان می دهد که چگونه یک آزمون t مستقل را با استفاده از SPSS Statistics انجام دهید، و همچنین نتایج این آزمون را تفسیر و گزارش کنید. با این حال، قبل از اینکه شما را با این روش آشنا کنیم، باید فرضیات مختلفی را که دادههای شما باید رعایت کنند تا یک آزمون t مستقل به شما یک نتیجه معتبر بدهد، بدانید. در ادامه به این فرضیات می پردازیم.
هنگامی که تصمیم می گیرید داده های خود را با استفاده از آزمون t مستقل تجزیه و تحلیل کنید، باید مطمئن شوید که آیا داده های شما واقعاً می توانند با استفاده از آزمون t مستقل تجزیه و تحلیل شوند یا نه. زیرا آزمون t مستقل تنها زمانی مناسب است که داده های شما از شش فرضی که برای یک آزمون t مستقل لازم است تا نتیجه معتبری به شما بدهد، «عبور کند». در عمل، بررسی این شش فرض کمی زمان بر است ولی در کل کار سختی نیست.
متغیر وابسته شما باید در مقیاس پیوسته اندازه گیری شود (یعنی در سطح فاصله ای (interval) یا نسبتی (ratio) اندازه گیری شود). نمونه هایی از متغیرهایی که این معیار را برآورده می کنند عبارتند از: زمان (اندازه گیری شده بر حسب ساعت)، هوش (اندازه گیری شده با استفاده از تست IQ)، نمره امتحان (اندازه گیری از 0 تا 20)، وزن (اندازه گیری شده بر حسب کیلوگرم) و غیره.
متغیر مستقل شما باید از دو گروه طبقه ای (categorical) و مستقل تشکیل شده باشد. نمونه متغیرهای مستقلی که این معیار را برآورده می کنند شامل جنسیت (2 گروه: مرد یا زن)، وضعیت اشتغال (2 گروه: شاغل یا بیکار)، فرد سیگاری (2 گروه: بله یا خیر) و غیره است.
مشاهدات شما باید مستقل (independence) باشد، به این معنی که هیچ رابطه ای بین مشاهدات در هر گروه یا بین خود گروه ها وجود ندارد. برای مثال، باید در هر گروه شرکتکنندگان متفاوتی وجود داشته باشد و هیچ شرکتکنندهای در بیش از یک گروه نباشد. این بیشتر یک موضوع طراحی مطالعه است تا چیزی که بتوانید آن را آزمایش کنید، اما یک فرض مهم برای آزمون t مستقل است. اگر مطالعه شما با این فرض شکست بخورد، باید به جای آزمون t مستقل از آزمون آماری دیگری استفاده کنید (به عنوان مثال، آزمون t-نمونه های جفت شده)
نباید داده های پرت (outliers) قابل توجهی وجود داشته باشد. داده های پرت صرفاً نقاط داده منفردی در دادههای شما هستند که از الگوی معمول پیروی نمیکنند. مشکل داده های پرت این است که می توانند تاثیر منفی بر آزمون t مستقل داشته باشند و اعتبار نتایج شما را کاهش دهند. خوشبختانه، هنگام استفاده از SPSS Statistics برای اجرای آزمون t مستقل بر روی داده های خود، می توانید به راحتی داده های پرت احتمالی را تشخیص دهید.
متغیر وابسته شما باید برای هر گروه از متغیر مستقل تقریباً به طور نرمال توزیع شود. ما در مورد آزمون t مستقل صحبت می کنیم که فقط به داده های تقریباً نرمال نیاز دارد، به این معنی که این فرض می تواند کمی نقض شود و همچنان نتایج معتبری ارائه دهد. شما می توانید نرمال بودن را با استفاده از آزمون نرمال Shapiro-Wilk که به راحتی برای استفاده از SPSS Statistics آزمون می شود، آزمون کنید.
باید همگنی واریانس ها (homogeneity of variances) وجود داشته باشد. می توانید این فرض را در SPSS Statistics با استفاده از آزمون Levene برای همگنی واریانس ها آزمایش کنید.
با استفاده از SPSS Statistics می توانید فرضیات #4، #5 و #6 را بررسی کنید. قبل از انجام این کار، باید مطمئن شوید که داده های شما با فرضیات #1، #2 و #3 مطابقت دارند، اگرچه برای انجام این کار به SPSS Statistics نیاز ندارید. هنگامی که به فرضیات #4، #5 و #6 می رویم، پیشنهاد می کنیم آنها را با این ترتیب گفته شده آزمایش کنید، زیرا نشان دهنده ترتیبی است که در آن، اگر نقض فرض قابل تصحیح نباشد، دیگر نمی توانید از آزمون t-مستقل استفاده کنید. فقط به یاد داشته باشید که اگر آزمون های آماری را بر اساس این فرضیات به درستی اجرا نکنید، نتایجی که هنگام اجرای آزمون t مستقل به دست می آورید ممکن است معتبر نباشند.
در بخش بعدی، ما روش SPSS Statistics مورد نیاز برای انجام یک آزمون t مستقل را با فرض اینکه هیچ فرضی نقض نشده است، نشان میدهیم. ابتدا، مثالی را که برای توضیح این روش در SPSS Statistics استفاده کرده ایم، را بیان میکنیم.
غلظت کلسترول در خون با خطر ابتلا به بیماری های قلبی مرتبط است، به طوری که غلظت بالاتر کلسترول نشان دهنده سطح بالاتر خطر و غلظت پایین تر نشان دهنده سطح خطر کمتر است. اگر غلظت کلسترول خون را کاهش دهید، خطر ابتلا به بیماری قلبی در شما کاهش می یابد. اضافه وزن و یا تحرک کم، غلظت کلسترول خون را افزایش می دهد. هم ورزش و هم کاهش وزن می توانند غلظت کلسترول را کاهش دهند. با این حال، مشخص نیست که آیا ورزش یا کاهش وزن برای کاهش غلظت کلسترول بهترین است یا نه. بنابراین، یک محقق تصمیم گرفت بررسی کند که آیا ورزش یا مداخله کاهش وزن در کاهش سطح کلسترول موثرتر است یا خیر. برای این منظور، محقق نمونهای تصادفی از مردان کم تحرک که دارای اضافه وزن بودند، را انتخاب کرد. سپس این نمونه به طور تصادفی به دو گروه تقسیم شد: گروه 1 تحت یک رژیم غذایی با کالری کنترل شده و گروه 2 برنامه تمرینی-ورزشی را بر عهده گرفتند. به منظور تعیین اینکه کدام برنامه درمانی مؤثرتر بود، میانگین غلظت کلسترول بین دو گروه در پایان برنامه های درمانی مقایسه شد.
در SPSS Statistics، با ایجاد یک متغیر گروهبندی شده به نام درمان ![]() (یعنی متغیر مستقل)، گروهها را برای تجزیه و تحلیل جدا کردیم. به «گروه رژیم غذایی» مقدار «1» و به «گروه ورزش» مقدار «2» دادیم (یعنی دو گروه متغیر مستقل). غلظت کلسترول تحت نام متغیر
(یعنی متغیر مستقل)، گروهها را برای تجزیه و تحلیل جدا کردیم. به «گروه رژیم غذایی» مقدار «1» و به «گروه ورزش» مقدار «2» دادیم (یعنی دو گروه متغیر مستقل). غلظت کلسترول تحت نام متغیر ![]() (یعنی متغیر وابسته) وارد شد.
(یعنی متغیر وابسته) وارد شد.
هشت مرحله زیر به شما نشان می دهد که چگونه داده های خود را با استفاده از آزمون t مستقل در SPSS Statistics تجزیه و تحلیل کنید، البته در صورتی که شش فرض گفته شده در بخش قبل، نقض نشده باشد. در پایان این هشت مرحله، نحوه تفسیر نتایج این آزمون را به شما نشان می دهیم.
همانطور که در زیر نشان داده شده است، روی
Analyze > Compare Means > Independent-Samples T Test…
در منوی اصلی کلیک کنید:
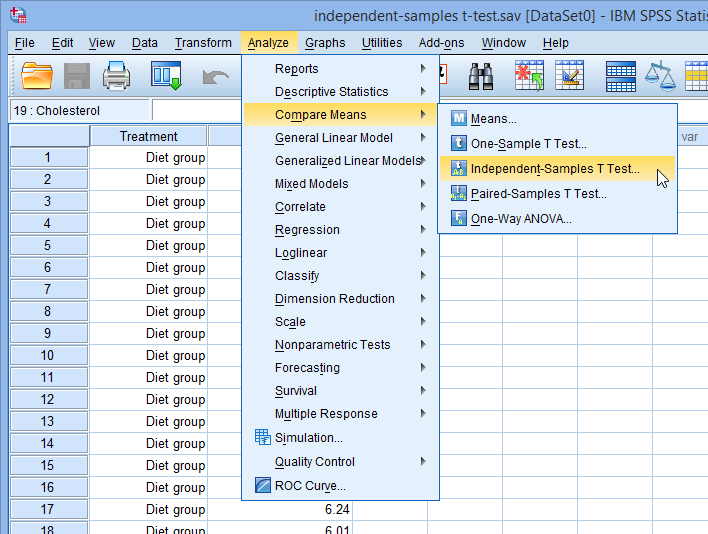
همانطور که در زیر نشان داده شده است، با پنجره ی Independent-Samples T Test نمایش داده می شود:
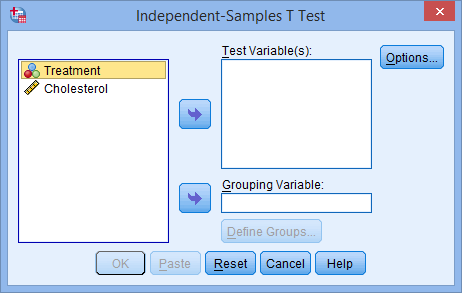
با برجسته کردن متغیرهای مربوطه و فشار دادن دکمههای فلش ![]() ، متغیر وابسته،
، متغیر وابسته، ![]() را به کادر Test Variable(s) و متغیر مستقل
را به کادر Test Variable(s) و متغیر مستقل ![]() ، را به کادر Grouping Variable انتقال دهید. در نهایت با صفحه زیر مواجه خواهید شد:
، را به کادر Grouping Variable انتقال دهید. در نهایت با صفحه زیر مواجه خواهید شد:
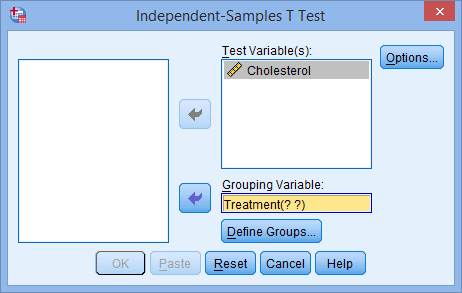
سپس باید گروه ها (treatments) را تعریف کنید. بر روی دکمه ![]() کلیک کنید. مطابق شکل زیر پنجره ی Define Groups نمایش داده می شود:
کلیک کنید. مطابق شکل زیر پنجره ی Define Groups نمایش داده می شود:
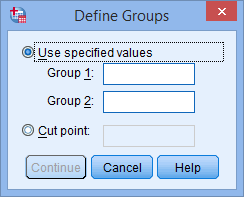
عدد “1” را در کادر Group 1 و عدد “2” را در کادر Group 2 وارد کنید. به یاد داشته باشید که با این کار ما گروه درمان رژیم غذایی را با عدد 1 و گروه درمان ورزشی را با عدد 2 کدگذاری و تعریف کردیم.
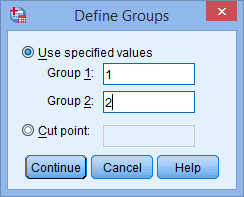
توجه: اگر بیش از 2 گروه درمانی در مطالعه خود دارید (به عنوان مثال، 3 گروه: گروه های رژیم غذایی، ورزش و درمان دارویی)، اما فقط میخواهید دو گروه را با هم مقایسه کنید (به عنوان مثال، گروه های رژیم غذایی و درمان دارویی)، میتوانید عدد 1 را در کادر Group 1 و عدد 3 را در کادر Group 2 وارد کنید (به عنوان مثال، اگر می خواهید رژیم غذایی (1) را با درمان دارویی (3) مقایسه کنید).
روی دکمه ![]() ادامه کلیک کنید.
ادامه کلیک کنید.
اگر میخواهید محدودیتهای سطح اطمینان را تغییر دهید یا نحوه حذف موارد را تغییر دهید، روی دکمه ![]() کلیک کنید. موارد زیر به شما ارائه خواهد شد:
کلیک کنید. موارد زیر به شما ارائه خواهد شد:
روی دکمه ![]() کلیک کنید. شما به پنجره ی Independent-Samples T Test بازگردانده می شوید.
کلیک کنید. شما به پنجره ی Independent-Samples T Test بازگردانده می شوید.
روی دکمه ![]() کلیک کنید.
کلیک کنید.
SPSS Statistics دو جدول اصلی خروجی را برای آزمون t مستقل تولید می کند. اگر دادههای شما از فرض شماره 4 (یعنی هیچ داده ی پرت مهمی وجود نداشت)، فرض شماره 5 (یعنی متغیر وابسته شما برای هر گروه از متغیر مستقل تقریباً به طور نرمال توزیع شده بود) و فرض شماره 6 (یعنی همگنی واریانسها وجود داشت) عبور کرد، فقط باید این دو جدول اصلی را تفسیر کنید. حتما قبل از آزمون، دادههای خود را برای این فرضیات آزمایش کنید. همچنین باید خروجی SPSS Statistics را که هنگام آزمایش برای آنها تولید شد، تفسیر کنید. به عنوان مثال، باید این موارد را تفسیر کنید: (الف) نمودارهای جعبهای (boxplots) برای بررسی وجود داده های پرت مهم، (ب) خروجی SPSS Statistics برای تست نرمال بودن Shapiro-Wilk و (ج) خروجی SPSS Statistics برای آزمون لوین (Levene’s) برای همگنی واریانس ها. به خاطر داشته باشید که اگر دادههای شما با هر یک از این فرضیات مواجه نشدند، خروجیای که از روش آزمون t مستقل به دست میآورید (یعنی جداولی که در زیر به آن اشاره میکنیم) ممکن است معتبر نباشد و ممکن است لازم باشد این جداول را متفاوت تفسیر کنید.
این جدول آمار توصیفی مفیدی را برای دو گروهی که مقایسه کردید، از جمله میانگین (mean) و انحراف استاندارد (standard deviation) ارائه می دهد.
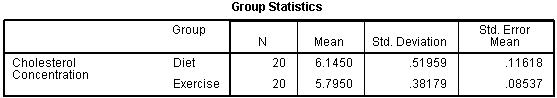
مگر اینکه دلایل دیگری برای انجام این کار داشته باشید، ارائه اطلاعات در مورد میانگین و انحراف استاندارد برای این داده ها نرمال تلقی می شود. همچنین می توانید تعداد شرکت کنندگانی را که در هر یک از دو گروه داشتید را ذکر کنید. این می تواند زمانی مفید باشد که مقادیر گم شده ای (missing values) داشته باشید و تعداد شرکت کنندگان استخدام شده بیشتر از تعداد شرکت کنندگان قابل تجزیه و تحلیل باشد.
همچنین می توان از یک نمودار برای ارائه بصری نتایج استفاده کرد. برای مثال، میتوانید از نمودار میلهای با error bars (میلههای خطا) استفاده کنید (به عنوان مثال، جایی که error bars میتوانند از انحراف استاندارد، خطای استاندارد یا فواصل اطمینان ۹۵٪ استفاده کنند). این می تواند درک نتایج را آسان تر کند.
این جدول نتایج واقعی آزمون t مستقل را ارائه می دهد.

می بینید که میانگین های گروه از نظر آماری تفاوت معنی داری دارند زیرا مقدار در ردیف Sig.(2-tailed) کمتر از 0.05 است. با نگاهی به جدول Group Statistics، میتوانیم متوجه شویم که افرادی که آزمایش ورزش را انجام دادهاند، در پایان برنامه نسبت به افرادی که تحت رژیم غذایی کنترلشده کالری قرار گرفتهاند، سطح کلسترول پایینتری داشتند.
بر اساس نتایج فوق، میتوانید نتایج مطالعه را به شرح زیر گزارش کنید (نکته، این گزارش شامل نتایج آزمایشهای فرضیات شما یا محاسبات اندازه اثر نمیشود):
این مطالعه نشان داد که شرکتکنندگان مرد دارای اضافه وزن و کم تحرک از نظر آماری غلظت کلسترول پایینتری (38/0 ± 80/5 میلیمول در لیتر) در پایان یک برنامه تمرینی در مقایسه با رژیم غذایی کنترلشده با کالری (52/0 ± 15/6 میلیمول در لیتر) داشتند.
t(38)=2.428, p=0.020
همچنین شایان ذکر است که علاوه بر گزارش نتایج آزمون t مستقل، انتظار می رود که شما نتایج حاصل از فرضیات و اندازه اثر را نیز گزارش دهید. راههای مختلفی مانند سبک های هاروارد و APA برای انجام این کار وجود دارد. اندازه اثر مهم است زیرا آزمون t مستقل فقط به شما می گوید که آیا تفاوت بین میانگین های گروه “واقعی” است (یعنی در جامعه متفاوت است)، اما “اندازه” تفاوت را به شما نمی گوید. ارائه اندازه اثر در نتایج به غلبه بر این محدودیت کمک می کند.
آلفای کرونباخ (Cronbach’s alpha) با استفاده از Minitab
آلفای کرونباخ (α) (Cronbach’s alpha) با استفاده از SPSS
نحوه تبدیل داده ها (Transforming Data) در SPSS
کاپای کوهن (Cohen’s kappa (κ)) با استفاده از SPSS
ایجاد نمودار میله ای با استفاده از SPSS
رسم نمودار پراکندگی (نقطه ای) (Scatterplot) با استفاده از SPSS
ایجاد نمودار میله ای خوشه ای (Clustered Bar Chart) با استفاده از SPSS
آنالیز کوواریانس چند متغیره (MANCOVA) یک طرفه در SPSS
آزمون علامت (sign test) با استفاده از SPSS
همبستگی حاصلضرب-گشتاور پیرسون (Pearson’s Product-Moment Correlation) با استفاده از SPSS Statistics
همبستگی دو رشته ای نقطه ای (Point-Biserial Correlation) با استفاده از SPSS
ضریب همبستگی رتبهای اسپیرمن (Spearman rank-order correlation coefficient) با استفاده از SPSS
همبستگی جزئی (Partial Correlation) با استفاده از SPSS
گامای گودمن و کروسکال (Goodman and Kruskal’s gamma) با استفاده از SPSS
آزمون H کروسکال-والیس (H Kruskal-Wallis) با استفاده از Stata
MANOVA یک طرفه با استفاده از Stata
آنالیز اجزای اصلی (PCA) با استفاده از SPSS
آمار توصیفی (descriptive) و استنباطی (inferential)
آزمون مربع کای (Chi-Square) با استفاده از SPSS
آزمون یو من ویتنی (Mann-Whitney U) با استفاده از SPSS
آزمون مک نمار (McNemar’s test) با استفاده از SPSS
کتاب سنجی (Bibliometrics) و تفاوت آن با علم سنجی (Scientometrics) و اطلاع سنجی (Informetrics)
تعدیل کننده دو وضعیتی (Dichotomous Moderator) با استفاده از SPSS
ضریب همبستگی تاوی- بی کندال (Kendall’s Tau-b correlation coefficient) با استفاده از SPSS
آزمون Jonckheere-Terpstra (جانكهير ترپسترا) با استفاده از SPSS
آزمون رتبه علامتدار ویلکاکسون (Wilcoxon signed-rank test) با استفاده از SPSS
آزمون Q کوکران (Cochran’s Q) با استفاده از SPSS
دی سامرز (Somers’ d) با استفاده از SPSS
آزمون t وابسته با استفاده از SPSS Statistics
آزمون t وابسته برای نمونه های جفت شده
رگرسیون لجستیک چند جمله ای در SPSS
رگرسیون لجستیک دو جمله ای با استفاده از SPSS
رگرسیون پواسون با استفاده از SPSS
ایجاد متغیر های ساختگی در SPSS
رگرسیون لجستیک ترتیبی با استفاده از SPSS
رگرسیون چندگانه با استفاده از SPSS
رگرسیون خطی با استفاده از SPSS
ANOVA مخلوط با استفاده از SPSS Statistics
ANOVA اندازه گیری های مکرر دو طرفه با استفاده از SPSS Statistics
ANOVA دو طرفه در SPSS Statistics
ANOVA با اندازه گیری های مکرر با استفاده از SPSS Statistics
آزمون نرمال بودن با استفاده از SPSS Statistics
انواع متغیر و تحقیقات تجربی و غیر تجربی
ANCOVA یک طرفه در SPSS Statistics
شصت لغت پرتکرار آزمون زبان عمومی آزمون دکتری
آزمون t نمونه تکی با استفاده از SPSS Statistics
چگونه یک نمودار نقطهای متصل به هم در R ایجاد کنیم؟
چند پروژه برای مبتدیان علم داده
شمارش تعداد در یک بردار منطقی در R
جایگزینی اولین مقدار غیر مفقود در R
انتساب داده های گمشده (Imputation of missing data) در R
برای یادگیری پایتون چه کتابایی بخونیم
چگونه نتایج حاشیه خطا را تفسیر کنیم؟
تحلیل سئوال روش تحقیق آزمون دکتری
تفاوت بین یادگیری ماشین، علم داده، هوش مصنوعی، یادگیری عمیق و آمار
تجزیه و تحلیل آماری: تعریف، مثال
روایی نتیجه گیری آماری (SCV) چیست؟
برنامه کلاس های آنلاین آمار و روش تحقیق
نحوه تعیین خودکار تعداد خوشه ها توسط قانون آرنج
هوش مصنوعی (AI) چیست؟ 3 چیز که باید بدانید
آمار و روش تحقیق در آزمون کارشناسی ارشد و دکتری روانشناسی
چهار مهارت افراد قدرتمند برای دانشمندان داده
چگونه یک سئوال تحقیق خوب طراحی کنیم؟
علم داده راه حلی برای مشکلات تجاری
بهترین کتاب های علوم داده برای مبتدیان
آمار در مقایسه با یادگیری ماشینی در سیستم های بیولوژیک
گراندد تئوری ادغام سنت های رشته ای متفاوت
مقدمه ای بر معادلات ساختاری و روش های آن
گوشه چشمی بر مفاهیم خوشه بندی در آمار و داده کاوی

یک پاسخ